


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
APPLICATION DEVELOPMENT FOR THE GENERATION OF EDUCATIONAL TASKS FOR TEXTS IN NATURAL LANGUAGE BASED ON GENERATED PATTERNS

В работе рассматривается проблема усовершенствования метода генерации учебных заданий на основе многомерного анализа семантических данных за счет привлечения алгоритма автоматической генерации используемых шаблонов.
На сегодняшний день широко распространены и разрабатываются разнообразные системы обучения иностранному языку.
Проблема разработки все больших объемов учебных материалов является актуальной в связи с внедрением творческих, гибких и индивидуальных траекторий обучения.
Проблема решается на стыке таких наук, как дискретная математика, математическая логика, теория формальных языков и грамматик.
Цель работы состоит в необходимости сформулировать некоторые принципы генерации учебных заданий, которые могут быть использованы при создании тестов для проверки знаний, в целях повышения эффективности процесса составления учебных материалов.
Задачи данной работы следующие:
1) описание принципа гибридизации многомерного представления семантических данных и порождающих грамматик;
2) разработка модуля порождающих грамматик для порождения шаблонов генерации;
3) разработка базы правил этой порождающей грамматики;
Основная идея работы состоит в расширении функциональности программы «Генератор учебных заданий», использующей многомерный анализ данных для анализа текста на английском языке и генерация тестовых материалов, за счет привлечения средств автоматической генерации специальных шаблонов, ссылающихся на разделы многомерной базы данных.
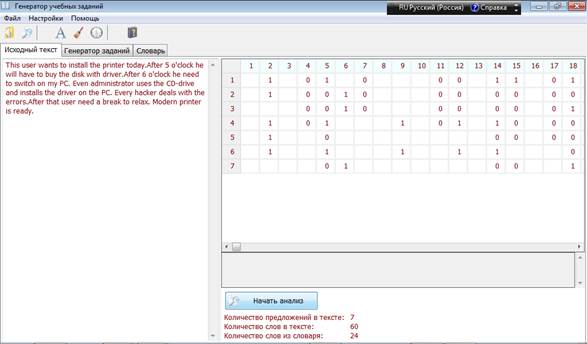
Рис.1. Главное окно программы с загруженным текстом и его визуализацией
Новизна данной работы состоит в гибридизации метода многомерного анализа данных, согласно анализу текста на английском языке с методом порождающих грамматик, применительно к генерации порождаемых шаблонов, ссылающихся на разделы многомерной базы данных, в целях генерации более разнообразных учебных материалов.
На сегодняшний день широко распространены и разрабатываются различные программы для обучения иностранному языку [7-9]. В связи с этим, генерация учебных заданий является актуальной проблемой.
Создание тестов для проверки знаний – это очень трудоемкий процесс, требующий много времени, так как задания составляются преподавателем самостоятельно, а также тесты должны меняться, чтобы избежать списывания со стороны обучающихся.
Появление IT-технологий привело преподавателей к попыткам автоматизировать процесс создания многовариантных заданий для своих курсов.
Целью данной работы является разработка приложения по генерации учебных заданий на основе порождаемых шаблонов на английском языке.
Проблема генерации осмысленных подмножеств естественного [1-6,10] языка является важной для решения проблемы автоматической генерации учебных заданий по иностранному языку.
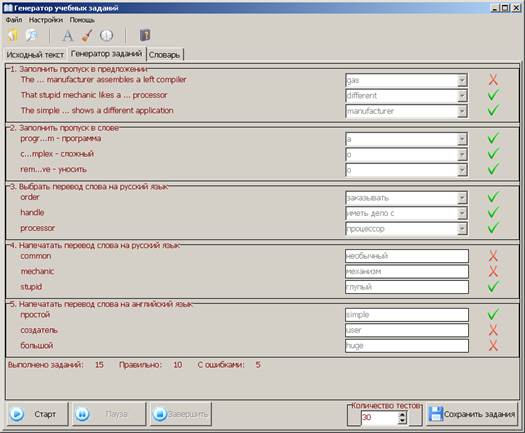
Рис. 2. Программа после выполнения проверки заданий
Коллективом авторов была разработана программа «Генератор учебных заданий». «Генератор учебных заданий» – это программный продукт, который обладает дружелюбным интерфейсом и ориентирован на пользователей, обладающих различным уровнем работы с компьютером. Данная программа получает в качестве входного параметра строку произвольного текста на английском языке с целью проанализировать его и обеспечить генерацию учебных заданий. Программа позволяет визуализировать структуру текста
(см. рис. 1).
В программу «Генератор учебных заданий» требуется внедрить порождаемые шаблоны, которые позволят сделать независимой систему порождения осмысленных фраз и заданий (см. рис. 2), как основы генерируемых учебных заданий.

Рис. 3. Сохранение сгенерированных заданий
Порождаемые шаблоны – шаблоны построения фраз естественного языка, которые могут быть заданы, как вручную, так и порождаться на основе, в частности, контекстно-свободных порождающих грамматик.
Они позволяют сделать систему независимой от способа создания, композиции и представления объектов.
Action + -ing + Link + -(e)s + Process + (Manner);
Action + -ing + the + Object + Link + -(e)s + Process + (Manner);
Action + -ing + was + Done + Group of Time;
Surely, + Action + -ing + was + Done + Group of Time.
Маркеры типа Action, Object обращаются к соответствующим ячейкам или группам ячеек условно трехмерного пространства данных с учетом текущей темы генерации учебных заданий.
На основе сгенерированных порождающей грамматикой шаблонов [5] модифицированная версия программы «Генератор учебных заданий» должна выдавать фразы следующего вида.
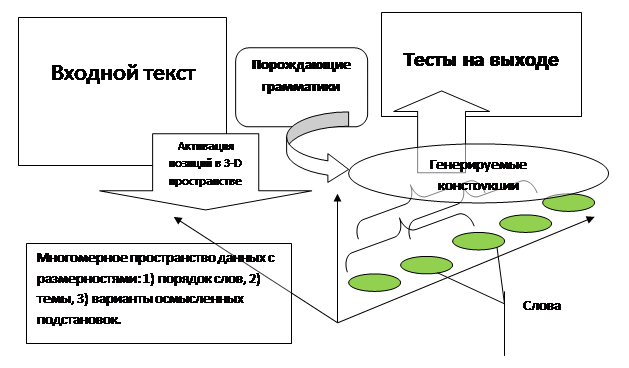
Рис. 4. Схема генерации осмысленных учебных заданий к текстам
«Eating the cake implies good appetite. Building means accuracy. Driving the bus presupposes interruptions. Driving the bus was carried out this morning. Obviously, knitting the coat was performed on Monday».
В качестве одного из этапов в направлении интерпретации текста на естественном языке необходимо осуществить проекцию слов каждого предложения такого текста с учетом реализуемой (в качестве побочного) эффекта экстракции семантического шума. На этом этапе необходимо приведение фраз текста к фразам приведенного вида с определенной вероятностью искажения смысла этих фраз, что технически не влияет на процесс генерации учебных заданий.
Так, например, входной текст «I am a programmer, preferring C++. C# is considered by some experts to be better…» подается на вход программы, после обработки предложений в многомерной базе данных активируются цепочки вида: «Programmer + (I) + program(s) in + C++. Some + expert(s) + consider + that + (it is) better (for) + programmers + (to) use + C#» на основе порядка слов приведенного вида: «Кто-то1 + думает/сообщает + (кому-то) + что + кто-то2 + склонен + иметь дело с + чем-то + где-то + когда-то + на основании какой-то информации + …», где для темы «Еда» это будут последовательностью вида: «… повар хочет готовить пиццу/курицу/котлеты …», а, например, для темы «Здания» – последовательностью вида: «…строитель может строить библиотеку/стадион/театр …». Ссылки порождающих грамматик относятся к вариантам выбора в многомерной базе данных, словам «комбинонимам», то есть словам, которые при замене друг друга в нужном контексте меняют смысл фраз, но сохраняют осмысленность: «(Я) + хочу/могу/пытаюсь/умею/должен + (приготовить + блюдо)». Далее на основе выборки из этих цепочек строятся учебные задания вида: Выберите правильный вариант подстановки: «is it worthy to program in C# / library / cake?».
Семантический шум представляет собой модель одного из проявлений естественного языка – творческого иносказания и трансформаций фраз человеком на основе определенного диапазона возможностей языка. Формально отвлекаясь от типов связей внутри фраз с семантическим шумом можно породить одну базовую интерпретацию текста на основе порядка терминов в многомерной семантической базе данных (см. рис. 4). Множество фраз неприведенного вида может быть получено из данной формы высказываний (функций над ячейками многомерной базы данных), полученные высказывания представляют собой иносказания стандартных фраз более или менее высокого художественного достоинства. На основе таких фраз строится множество учебных заданий, интегрируемых в различные варианты тестов (см. рис. 3).
Очевидно, что само смысловое значение, включающее все ассоциативные и эмоциональные компоненты, не может быть формализовано на основе простого вектора рационально представленных иррационально-смысловых категорий. Но в рамках определенных аппроксимаций и приближений возможно описывать семантику естественного языка до уровня достаточного для решения конкретных инженерных задач разной степени сложности. В перспективе на основе семантического понятийного аппарата имеется принципиальная, хотя и чрезвычайно сложная, задача прохождения теста Тьюринга лингвистическим программным обеспечением. При этом остается актуальным разработка программных систем с более узкой функциональной направленностью, в частности, рассматриваемый программный продукт.
В рамках такого рода работы над узким набором задач необходимо развивать принципы генерации осмысленной речи на основе проработки отдельных подмножеств многомерной классификации слов и понятий языка с учетом возможности использования этих фрагментов для генерации подмножеств естественного языка. Необходима реализация этих принципов на основе генерируемых (порождающими грамматиками) семантических шаблонов с извлечением из их структуры семантического шума с частичными семантическими потерями.
Порождение шаблонов генерации осмысленной речи, ссылающихся на ячейки многомерной базы данных, может быть осуществлено при помощи порождающих грамматик и впоследствии уточняться на основе введения операций над векторами сем, когда будут вводиться запреты на подмножества комбинаций фраз, генерируемых на основе принципа семантических подстановок. Данная программа может позволить составлять различные варианты заданий одного типа. Множества вариантов генерируемых шаблонов позволят индивидуализировать задания, так как большое количество тестовых материалов необходимо для исключения списывания со стороны студентов и учеников. Также она позволит обеспечить экономию времени на разработку образовательных ресурсов преподавателям.
В статье рассматривается проблема гибридизации принципа генерации осмысленных заданий и фраз естественного языка на основе многомерных баз данных и принципа генерации проецируемых на неё шаблонов фраз, на основе контекстно-свободных порождающих грамматик, и реализация этого подхода при разработке и усовершенствовании программы «Генератор учебных заданий», которая будет способствовать автоматизации работы преподавателей по разработке электронных образовательных ресурсов, а также позволит ускорить процесс разработки тестов на основе печатных материалов.
Рецензенты:
Ченцов С.В., д.т.н., профессор, заведующий кафедрой Системы автоматики, автоматизированного управления и проектирования Сибирского федерального университета, г. Красноярск;
Бронов С.А., д.т.н., профессор, руководитель научно-учебной лаборатории Систем автоматизированного проектирования кафедры Системы искусственного интеллекта Сибирского федерального университета, г. Красноярск.
Библиографическая ссылка
Личаргин Д.В., Усова А.А., Сотникова В.В., Липман С.А., Бутовченко В.В. РАЗРАБОТКА ПРИЛОЖЕНИЯ ПО ГЕНЕРАЦИИ УЧЕБНЫХ ЗАДАНИЙ К ТЕКСТУ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ ПОРОЖДАЕМЫХ ШАБЛОНОВ // Современные проблемы науки и образования. 2015. № 2-2. ;URL: https://science-education.ru/en/article/view?id=22636 (дата обращения: 15.06.2026).