


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
MODIFICATION OF ALGORITHM OF OPTIMIZATION SEQUENCE SELECTION FOR SOLVING THE TRAVELLING SALESMAN PROBLEM

Задача коммивояжера уже около 100 лет привлекает внимание исследователей по дискретной математике по всему миру [2– 9]. Задача коммивояжера – найти кратчайший маршрут, по которому он сможет посетить все требуемые города по одному разу и вернуться в пункт отправления. Существуют разновидности этой задачи. В данной работе рассмотрена симметричная задача (когда расстояния между городами в прямом и обратном направлении одинаковы), геометрическая (расстояния между городами отражают расстояния между точками на плоскости), метрическая (выполняется неравенство треугольника). Задача относится к классу NP-полных задач, т.е. ее решение методом рассмотрения всех вариантов невозможно из-за экспоненциального роста числа вариантов даже при небольшом увеличении числа городов.
В последние десятилетия для решения этой задачи применяются наряду с давно известными методами, такими как жадный алгоритм, метод ветвей и границ, также метаэвристические алгоритмы:
1) метод множественного старта [9];
2) метод роя частиц [5];
3) генетический алгоритм [8];
4) гибридные (например, поиска с запретами и целочисленного программирования [7]);
5) метод имитации отжига [3];
6) метод муравьиной колонии [4] и иные, менее известные.
В работе [1] предложен ряд алгоритмов, которые успешно применялись, в частности, для оптимизации в имитационной модели расписания учебных занятий. Названий они не имели, только нумеровались. Последний из алгоритмов в статье [1] назовем алгоритмом оптимизации последовательности отбора. Он достигал наилучших результатов среди всех предложенных алгоритмов, а также ряда известных алгоритмов: генетических, имитации отжига, множественного старта и их комбинаций. Впоследствии было также определено, что результаты лучше, чем результаты методов роя частиц и муравьиной колонии. В связи с этим предполагается, что он будет эффективно работать и с другими оптимизационными задачами.
Цель работы – рассмотреть применение алгоритма оптимизации последовательности отбора к решению задачи коммивояжера.
Адаптация алгоритма оптимизации последовательности отбора к решению задачи коммивояжера
В исходном виде алгоритм оптимизации последовательности отбора [1] применен к задаче размещения (расположения объектов на временной шкале), которая имитирует составление учебного расписания. Алгоритм заключается в имитации отжига, но не самого размещения, как это обычно делается, а последовательности применения данных об объектах для эвристики размещения, основанной на исследовании локальной области. При этом параметр «температура», обозначаемый T, имеет тот же смысл, что и ранее. Применим алгоритм к задаче коммивояжера, в которой множество городов обозначим G = {gi, 1 ≤ i ≤ n}, где n – количество городов.
Во-первых, определим соответствующую локальную эвристику. В качестве данной эвристики в работе применен метод ближайшего соседа, т.е. при выборе следующего города gi+1 в маршруте выбирается тот, который ближе всего к текущему городу gi, где 1 ≤ i < n. Расстояние между gi и gi+1 обозначим Δi. Задачи выбора следующего города от gn нет, так как это всегда g1.
Во-вторых, определим, что означает последовательность. Для этого примем, что в отличие от метода ближайшего соседа допускаются небольшие отклонения в сторону увеличения расстояния Δi, не более некоторого числа ε. В итоге появляется несколько ближайших городов – список ψi, в котором |ψi| элементов. Список ψi упорядочен по увеличению расстояний δj входящих в него городов от gi, где δj ≤ Δi + ε, 1 ≤ j ≤ |ψi|. Становится возможным выбрать любой город из ψi, а не только один ближайший. Последовательностью будет список номеров M = {mi}, каждый из которых представляет собой порядковый номер элемента списка ψi, где 1 ≤ i < n.
В-третьих, необходимо не допускать слишком большого e, иначе ожидается, что метод станет неэффективным. В программной реализации, например, e уменьшается пропорционально снижению T.
В алгоритме используются следующие параметры, корректируемые пользователем в программе (табл. 1).
Таблица 1
Параметры алгоритма
|
Смысловые значения |
Числовые значения* |
|
Исходная (наивысшая) температура T0 |
2 |
|
Исходное число итераций (при T0) |
6500 |
|
Вероятность P перехода к худшему значению |
10 |
|
Увеличение числа итераций при ступенчатом снижении T |
2500 |
|
Число E городов, для которых ε > 0 (последовательных в маршруте) |
39 |
|
Номер города g1, с которого начинается построение маршрута |
29 |
|
Число S изменений в последовательности |
11 |
|
Множитель F на среднее расстояние между городами |
0,05 |
* при которых достигнуто наилучшее решение из найденных для файла f1, см. ниже
Алгоритм следующий.
1. Вычислить среднее расстояние A между городами.
2. Чтение параметров, задаваемых пользователем.
3. Обнулить маршрут.
4. mi ← 1, где 1 ≤ i ≤ n (т.е. выбрать первые города из ψi). Найденный за все время минимум длины маршрута MIN ← 1000000.
5. Имитация отжига со стандартными параметрами – T = T0, число итераций и др.:
5.0. Увеличить максимальное число итераций. Номер итерации I ← 0.
5.1. I ← I +1. Изменение mi случайным образом (на ±1), причем вероятность изменения пропорциональна S, а вероятность увеличения обратно пропорциональна i, где 1 ≤ i ≤ E.
5.2. Считать g1 из введенных данных.
5.3. Нахождение следующего города для каждого города i, начиная с первого до предпоследнего:
5.3.1. Найти расстояние Δ до ближайшего города
5.3.2. Выбрать следующий город, пропуская mi – 1 более близких, при этом увеличение расстояния по сравнению с Δ не должно превышать ε = A×F×I /10, иначе выбирается город, пропуская mi – 2.
5.4. Подсчитать общую длину маршрута L.
Проверка условия имитации отжига для внесения изменений в M:
L ≤ MIN, либо L > MIN и:
random(P / (T0 – T)) > 6 и L – MIN < (P/(T0 – T)).
Если не выполнено, откат M на состояние до изменений.
5.5. Конец очередной итерации. Если не все итерации совершены, переход на 5.1.
5.6. Уменьшить T.
5.7. Если T ≥ 0, переход на 5.0;
6. Конец
Программа и исходные данные
Для реализации данного алгоритма разработана компьютерная программа в свободно распространяемой системе программирования Turbo Delphi 2006. Программа работает в операционной системе Windows, позволяет использовать подготовленные вручную исходные данные и генерировать их случайным образом. Число городов ограничено 40, но нетрудно перекомпилировать программу и для большего числа городов. Программа реализует также стандартный метод имитации отжига и метод ближайшего соседа.
В качестве исходных данных взяты широко известные наборы данных [6], специфические для задачи коммивояжера. В разных наборах [6] используется различный формат представления данных, и для каждого нужно разрабатывать собственную процедуру чтения входных данных. Поэтому использованы также наборы данных на основе входных файлов работы [1], которые представлены в ней в виде диаграммы. Эти файлы унифицированы по формату, и их легче использовать в программе. Кроме того, экспорт алгоритма в другую задачу облегчается экспортом тех же исходных данных.
В файлах [1] в качестве координат городов использованы характеристики объектов. Первая половина данных файла, ранее представлявшая значимости объектов ti, i=1,…n, теперь используются как набор значений по оси абсцисс (упрощенно, географические долготы городов). Вторая половина представляла длительности (ширины) pi, i=1,…n, теперь они применяются как значения по оси ординат (соответственно, географические широты). При открытии файла программа вычисляет евклидовы расстояния между каждой полученной точкой на плоскости. Эти расстояния принимаются за исходные данные для задачи коммивояжера. Координаты городов являются целочисленными, а расстояния между ними могут быть вещественными числами.
Результаты эксперимента
На рис. 1 представлена экранная форма, содержащая результаты работы нового алгоритма с данными файла f1 [1], которые приводятся в таблице 2.
Таблица 2
Данные файла f1
|
№ города |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Долгота |
10 |
12 |
11 |
5 |
5 |
2 |
12 |
13 |
10 |
9 |
|
Широта |
12 |
16 |
15 |
66 |
64 |
32 |
15 |
14 |
15 |
2 |
|
№ города |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
Долгота |
1 |
20 |
20 |
20 |
10 |
10 |
8 |
12 |
11 |
30 |
|
Широта |
3 |
8 |
16 |
35 |
36 |
74 |
61 |
12 |
17 |
25 |
|
№ города |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
|
Долгота |
14 |
10 |
20 |
1 |
20 |
30 |
10 |
3 |
4 |
15 |
|
Широта |
28 |
40 |
16 |
52 |
25 |
25 |
25 |
25 |
13 |
19 |
|
№ города |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
|
Долгота |
16 |
12 |
90 |
14 |
80 |
12 |
12 |
80 |
60 |
40 |
|
Широта |
87 |
46 |
23 |
15 |
46 |
46 |
18 |
45 |
51 |
61 |
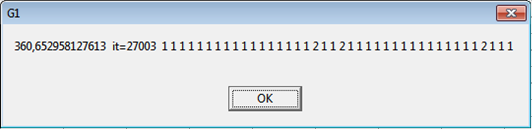
Рис. 1. Результат при использовании нового алгоритма для файла f1
— первое число (вещественное) – полученная длина маршрута;
— второе число – количество совершенных итераций;
— все остальные числа – последовательность M, специфичная для данного алгоритма.
На рисунке 2 приводится иллюстрация наилучшего из найденных новым алгоритмом маршрутов с данными файла f1.
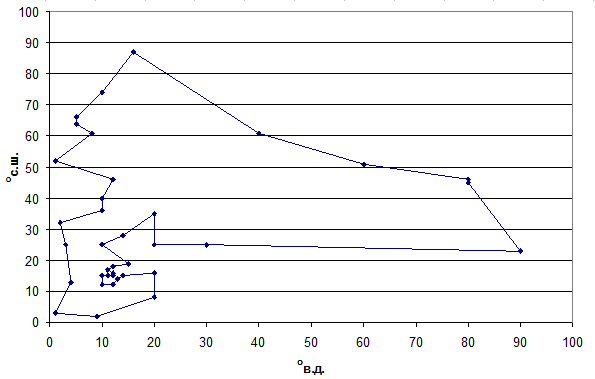
Рис. 2. Вид наилучшего из найденных маршрутов для файла f1
Города обозначены маркерами
Для обобщения результатов рассмотрена работа различных алгоритмов решения задачи коммивояжера с различными по статистическим характеристикам исходными данными (табл. 3).
Таблица 3
Результаты работы различных алгоритмов с различными исходными данными
|
Файл |
Результат метода ближайшего соседа |
Результат нового алгоритма |
При этом совершено итераций |
Результат метода имитации отжига |
При этом совершено итераций |
|
fri26.tsp |
965 |
937 |
26008 |
937 |
102004 |
|
gr48.tsp |
5840 |
5284 |
26008 |
5313 |
600006 |
|
f1 |
366,425 |
360,653 |
27003 |
360,653 |
32004 |
|
f2 |
625,756 |
536,528 |
26008 |
594,051 |
700008 |
|
f3 |
121,955 |
98,643 |
23004 |
109,71 |
180004 |
|
f4 |
56,717 |
53,755 |
12505 |
56,717 |
172004 |
|
f6 |
693,415 |
640,169 |
26008 |
639,699 |
172004 |
Данные таблицы 2 позволяют сделать вывод, что из трех алгоритмов метод ближайшего соседа приводит к значительно менее оптимальным результатам, а новый алгоритм нередко позволяет получить наилучшие результаты.
Заключение
Недостатком нового алгоритма является низкая скорость вычислений. При использовании нового алгоритма скорость составляет около 7200 итераций в секунду, а при имитации отжига – около 350 000 итераций в секунду. Однако при сопоставлении этих двух методов иногда новый алгоритм достигает лучших результатов, и количество итераций для этого требуется меньше. Таким образом, адаптация алгоритма оптимизации последовательности отбора к решению задачи коммивояжера успешно проведена.
Рецензенты:
Соснин П.И., д.т.н., профессор кафедры вычислительной техники Ульяновского государственного технического университета, г. Ульяновск;
Макарычев П.П., д.т.н., профессор кафедры математического обеспечения и применения ЭВМ Пензенского государственного университета, г. Пенза.
Библиографическая ссылка
Димитриев А.П. МОДИФИКАЦИЯ АЛГОРИТМА ОПТИМИЗАЦИИ ПОСЛЕДОВАТЕЛЬНОСТИ ОТБОРА ДЛЯ РЕШЕНИЯ ЗАДАЧИ КОММИВОЯЖЁРА // Современные проблемы науки и образования. 2015. № 2-1. ;URL: https://science-education.ru/en/article/view?id=20628 (дата обращения: 29.07.2026).