


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
THE EFFECT OF ROUTE SINGULARITY IN DIGITAL MODULES

В процессе проектирования современных микропроцессорных систем обычно требуется реализовать одновременное выполнение высоких требований к быстродействию, надежности функционирования и габаритным показателям системы в модульном исполнении. Указанные требования зачастую являются противоречивыми. В частности, уменьшение габаритов аппаратных средств (модуля) усложняет трассировку системной магистрали: оказывается невозможным параллельное размещение всех ее линий на многослойной печатной плате с реальной топологией. В результате задержки сигналов, распространяющихся по различным линиям от одного компонента системы к другому, имеется значительное временное рассогласование. Причем рассогласование проявляется тем более существенно (в смысле понижения надежности из-за случайных сбоев), чем выше требования к быстродействию, приводящие к повышению частоты синхронизации системы. Кроме того, в многопроцессорных системах смена ведущего компонента ведет к такому изменению задержек сигналов, распространяющихся от этого компонента к ведомым компонентам и в обратном направлении, которое тоже весьма существенно при высоком быстродействии.
По указанным выше причинам возникает необходимость детального анализа проектируемых систем, в частности детального анализа временных соотношений (взаимных задержек) для распространяющихся в них сигналов.
Подобный анализ синхронного обмена проводится, например, в [4], но не учитывает влияние особенностей трассировки системной магистрали и линий системной синхронизации на многослойной печатной плате.
Нашей задачей является уточнение методики анализа временных соотношений для сигналов, распространяющихся в быстродействующих цифровых многопроцессорных модулях при синхронном обмене данными, что позволит избежать грубых ошибок в процессе проектирования.
В соответствии с поставленной задачей проведем анализ временных соотношений в мультипроцессорной системе (МПС) с учетом особенностей трассировки системной магистрали и линий системной синхронизации.
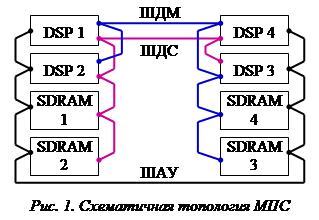
Компоненты мультипроцессорной системы связаны между собой системной магистралью, которая содержит три двусторонние (мультиплексированные) системные шины: шину адреса и управления (ШАУ), шину обмена старшими разрядами (от 63-го до 32-го) данных (ШДС) и шину обмена младшими разрядами (от 31-го до 0-го) данных (ШДМ).
Топология системных шин на печатной плате может существенно различаться, как схематично показано на рис. 1, что приводит к существенному временному рассогласованию сигналов.
В мультипроцессорной системе из ![]() подключенных к шине компонентов
подключенных к шине компонентов ![]() могут быть ведущими (Master), т.е. управлять обменом по шине. Смена ведущего (обычно процессора) приводит к перераспределению задержек распространения сигналов от ведущего к ведомым (Slave) и задержек сигналов тактовой частоты.
могут быть ведущими (Master), т.е. управлять обменом по шине. Смена ведущего (обычно процессора) приводит к перераспределению задержек распространения сигналов от ведущего к ведомым (Slave) и задержек сигналов тактовой частоты.
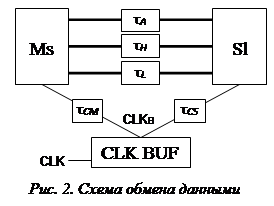
Синхронный обмен данными по системной магистрали МПС выполнятся по схеме ведущий-ведомый (Master-Slave) или Ms-Sl, как показано на рис. 2. При этом в каждом определенном цикле обмена ведущим является один из процессоров, а ведомым (или ведомыми) – один или несколько из оставшихся компонентов. Следует отметить, что между двумя любыми компонентами МПС существует единственный путь распространения конкретного сигнала.
На рис. 2 ![]() – задержка (время) распространения сигналов между Ms и Sl по шине ШАУ, ШДС или ШДМ соответственно;
– задержка (время) распространения сигналов между Ms и Sl по шине ШАУ, ШДС или ШДМ соответственно; ![]() – задержка сигнала тактовой частоты от тактового буфера CLK BUF до ведущего компонента;
– задержка сигнала тактовой частоты от тактового буфера CLK BUF до ведущего компонента; ![]() – задержка сигнала тактовой частоты до ведомого компонента.
– задержка сигнала тактовой частоты до ведомого компонента.
Очевидно, что ![]() (каждая из этих трех величин) определяется трассировкой печатной платы, как детально показано в [1].
(каждая из этих трех величин) определяется трассировкой печатной платы, как детально показано в [1].
Для мультипроцессорной системы блочную матрицу задержек Т размера ![]() (блоков) можно представить:
(блоков) можно представить:
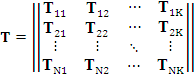 ,
,
где каждый блок размером 1×3
![]() ;
;
![]() – задержка распространения сигналов по участку ШАУ, которым связаны n-й и k-й компоненты МПС;
– задержка распространения сигналов по участку ШАУ, которым связаны n-й и k-й компоненты МПС;
![]() – задержка распространения сигналов по участку ШДС, которым связаны n-й и k-й компоненты МПС;
– задержка распространения сигналов по участку ШДС, которым связаны n-й и k-й компоненты МПС;
![]() – задержка распространения сигналов по участку ШДМ, которым связаны n-й и k-й компоненты МПС;
– задержка распространения сигналов по участку ШДМ, которым связаны n-й и k-й компоненты МПС;
![]() ;
;
![]() ;
;
![]() – количество ведущих компонентов МПС;
– количество ведущих компонентов МПС;
![]() – общее количество компонентов МПС.
– общее количество компонентов МПС.
С целью упрощения дальнейшего использования в расчетах сформируем блочную матрицу M размера ![]() (блоков):
(блоков):
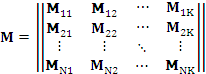 ,
,
где каждый блок размером 1×4
![]() ;
;
![]()
![]()
![]()
![]()
Кроме того, опишем блочной матрицей C размера 1×K связи CLK BUF c компонентами МПС, реализуемые соответствующими печатными проводниками:
![]() ,
,
где каждый блок размером 1×2
![]() ;
;
где ![]() – минимальная задержка распространения сигнала по печатному проводнику, связывающему буфер CLK BUF с k-м компонентом МПС;
– минимальная задержка распространения сигнала по печатному проводнику, связывающему буфер CLK BUF с k-м компонентом МПС;
![]() – максимальная задержка распространения сигнала по печатному проводнику, связывающему буфер CLK BUF с k-м компонентом МПС.
– максимальная задержка распространения сигнала по печатному проводнику, связывающему буфер CLK BUF с k-м компонентом МПС.
И, наконец, вычислим в соответствии с [1; 5] блочную матрицу D размера ![]() запаса по времени задержки сигналов:
запаса по времени задержки сигналов:
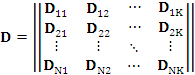 ,
,
где каждый блок размером 1×4
![]() ;
;
![]() – время предустановки для цикла ЗАПИСЬ;
– время предустановки для цикла ЗАПИСЬ;
![]() – время удержания для цикла ЗАПИСЬ;
– время удержания для цикла ЗАПИСЬ;
![]() – время предустановки для цикла ЧТЕНИЕ;
– время предустановки для цикла ЧТЕНИЕ;
![]() – время удержания цикла ЧТЕНИЕ;
– время удержания цикла ЧТЕНИЕ;
![]() – временные параметры, не зависящие от трассировки и рассчитанные по методикам [4].
– временные параметры, не зависящие от трассировки и рассчитанные по методикам [4].
Для надежной работы системной шины элементы матрицы D должны быть неотрицательными.
Изложенная методика оценки временных параметров системной шины с учетом задержек передаваемых сигналов реальными линиями шины применялась в процессе проектирования мультипроцессорного кластера при его реализации на отечественной элементной базе – на базе высокопроизводительных процессоров цифровой обработки сигналов (ВПЦОС), разработанных и производимых в ЗАО «ПКК Миландр» [3].
Принципиальная схема кластера выполнена по структуре, приведенной в [2], внешний вид процессорного кластера показан на рис. 3, топология системных шин схематично показана на рис. 1.

Рис. 3. Внешний вид мультипроцессорного кластера
Кластер содержит четыре процессора ВПЦОС [2] (DSP1-DSP4 на рис. 1), четыре микросхемы синхронной динамической памяти (SDRAM1-SDRAM 4 на рис. 1), загрузочное ПЗУ, тактовый буфер, тактовый генератор и вспомогательные источники питания.
Частота работы системной шины 100 МГц, разрядность данных 64 бита.
Конструктивно мультипроцессорный кластер выполнен на 16-слойной печатной плате размером 80×150 мм (рис. 3), содержит 404 элемента, соединенных 525 цепями.
Особенностью разработанного мультипроцессорного кластера является возможность межпроцессорного обмена данными, когда любой из четырех процессоров (ведущий, Master) имеет доступ к внутренней памяти и регистрам другого (ведомого, Slave) или всех остальных (в режиме широковещательного обмена, Broadcast).
Для расчета и анализа временных задержек с учетом трассировки платы использовалась схема, показанная на рис. 4.
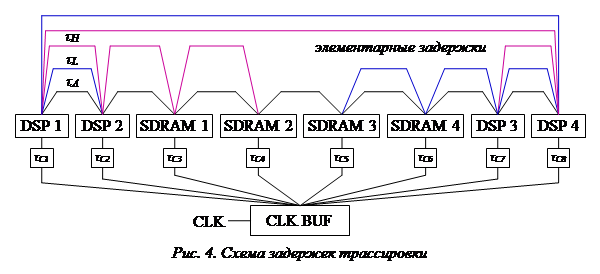
Таким образом, развитая в данной работе методика учета особенностей трассировки при анализе временных соотношений для сигналов, распространяющихся в быстродействующих цифровых модулях при синхронном обмене данными, обеспечивает возможность оценки работоспособности для выбираемых вариантов проектирования.
Работа выполнена при поддержке Министерства образования и науки в рамках договора № 02.G25.31.0061 от 12 февраля 2013 года (в соответствии с Постановлением Правительства Российской Федерации от 9 апреля 2010 г. № 218).
Рецензенты:
Хранилов В.П., д.т.н., профессор кафедры компьютерных технологий в проектировании и производстве Нижегородского государственного технического университета имени Р.Е. Алексеева, г. Нижний Новгород;
Флаксман А.Г., д.ф.-м.н., профессор кафедры бионики и статистической радиофизики Нижегородского государственного университета имени Н.И. Лобачевского, г. Нижний Новгород.
Библиографическая ссылка
Кузин А.А., Плужников А.Д., Приблудова Е.Н., Сидоров С.Б. ВЛИЯНИЕ ОСОБЕННОСТЕЙ ТРАССИРОВКИ В ЦИФРОВЫХ МОДУЛЯХ // Современные проблемы науки и образования. 2015. № 1-1. ;URL: https://science-education.ru/en/article/view?id=19343 (дата обращения: 01.07.2026).