


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
IDENTIFICATION METHODS FOR NONLINEAR CONTROL SYSTEMS

Для решения задачи идентификации нелинейных объектов разработано довольно много подходов и методов [4, 7]. На современном этапе возросли требования к точностным характеристикам применяемых алгоритмов идентификации. В связи с этим модифицируются классические подходы к решению задачи идентификации нелинейных систем с целью повышения их точности и уменьшения ограничений применения [3], а также универсальные поисковые методы, которые требуют минимальной априорной информации об идентифицируемой системе, но сложны в реализации.
К последним относятся генетические алгоритмы многопараметрического поиска решений, адекватно описывающих значения параметров исследуемой системы, а также различные методы самоорганизации и нейронные сети [2, 5, 6, 11].
В настоящей статье представлены наиболее значимые методы идентификации нелинейных систем автоматического управления, показаны их достоинства и недостатки, предложна модификация классического метода Вольтерра, основанная на упрощении реализации алгоритма.
1. Современные методы идентификации нелинейных систем.
При проектировании систем управления различными динамическими объектами часто необходимо иметь нелинейную математическую модель исследуемого процесса. Подобные нелинейные модели используются также для прогнозирования состояния объекта и параметров внешней среды, на основе которых осуществляется анализ и выработка управленческих воздействий.
Рассмотрим некоторые методы идентификации нелинейных систем, применяемые на практике. Одним из популярных методов идентификации является алгоритм идентификации на основе разложения функционалов Винера [7]. В результате реализации этой процедуры определяются наборы оптимальных ядер Винера, определяемые взаимокорреляционным методом
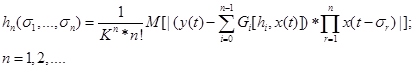 (1)
(1)
Задачу определения ядер Винера можно считать корректной, только если на вход исследуемой системы подается идеальный белый шум. Такой процесс реализовать на практике не представляется возможным, поэтому возникает проблема выбора оптимальных параметров тестирующего сигнала, обеспечивающих восприятие этого сигнала системой, как белый шум. Для получения точных оценок характеристик исследуемой системы необходимо выбрать частотный диапазон тестирующего сигнала. Но чтобы входной гауссов процесс для системы был белым шумом, частотный диапазон должен полностью перекрывать полосу пропускания системы, а он сам в пределах этой полосы должен обладать постоянной спектральной плотностью.
На практике из-за ограниченности спектральной полосы тестирующего сигнала оценки ядер Винера являются смещенными [3]. Выбрать оптимальный частотный диапазон тестирующего сигнала, ориентируясь на полосу пропускания, возможно только для линейных систем. Для нелинейных же систем данная характеристика не является информативной.
Для получения уточненных оценок ядер разработан алгоритм дифференцированного подхода к выбору оптимального частотного диапазона тестирующего сигнала, т.е. для каждого порядка рассчитываемых ядер предлагается определять свой оптимальный частотный диапазон теста. Однако такой подход сложен в реализации, особенно на борту динамического объекта.
Современные поисковые алгоритмы в практических приложениях представлены в основном алгоритмами самоорганизации, нейронными сетями и генетическими алгоритмами.
Генетические алгоритмы оперируют с популяцией оценок потенциальных решений (индивидуумов), используя принцип «выживает наиболее приспособленный». На каждом шаге алгоритма образуется новое множество приближений, создаваемое посредством процесса отбора индивидуумов согласно их уровню пригодности. Операндом генетического алгоритма является ген G – закодированная оценка того или иного осложнения технологического режима, объединенный в «хромосому» – n-мерный вектор ![]() . Область всех значений генов G унифицирована – [0…7], что обеспечивает возможность применения операторов генетических алгоритмов между ними. Размерность кода зависит от требуемой точности оценки прогнозируемых параметров. Значение кода G определяет количественную оценку осложнения, которая может быть пропорциональной или прогрессивной [9].
. Область всех значений генов G унифицирована – [0…7], что обеспечивает возможность применения операторов генетических алгоритмов между ними. Размерность кода зависит от требуемой точности оценки прогнозируемых параметров. Значение кода G определяет количественную оценку осложнения, которая может быть пропорциональной или прогрессивной [9].
Однако, генетические алгоритмы плохо масштабируемы под сложность решаемой проблемы. Это значит, что число элементов, подверженных мутации очень велико, если велик размер области поиска решений. Для того чтобы сделать так, чтобы такие проблемы поддавались эволюционным алгоритмам, они должны быть разделены на простейшие представления. Но тогда требуется хорошая совместимость этих представлений с другими частями в процессе оценки пригодности [12].
Нейросеть представляет собой структуру, состоящую из множества однотипных элементов – нейронов, соединенных между собой синаптическими связями. Нейронные сети позволяют построить модели исследуемых объектов с достаточно высокой точностью, но требуют при этом длительного времени для реализации процесса обучения. Основной задачей построения и обучения нейронной сети является аппроксимация функции. Имея обучающую выборку входных данных и значений функции, требуется определить весовые коэффициенты нейронной сети так, чтобы результат работы сети (значение выходной функции) на векторе входных переменных был как можно ближе к заданному значению функции (обучающему значению) для этого вектора.
Обучение нейронной сети происходит по следующему алгоритму: 1) первоначальные веса задаются случайным образом; 2) реализуется эпоха обучения; 3) проверяются условия завершения работы нейронной сети. В процессе реализации эпохи обучения нейронной сети для всех входных векторов по очереди осуществляются следующие процедуры: 1) значения входного вектора пропускаются через сеть и определяется результат работы сети; 2) определяется отклонение результата сети от исходного значения; 3) изменяются веса связей элементов сети от последних слоев к первым. Изменение происходит в соответствии с методом градиентного спуска. Целью является найти минимум ошибки для каждого элемента. После того как прошел процесс обучения проверяется условие окончания функционирования алгоритма. А именно, насколько результаты работы нейронной сети отличаются от исходных значений. Если условие еще не выполнено, то алгоритм возвращается ко второму шагу. Если отклонение от исходной выборки удовлетворяет условиям, заданным в алгоритме априорно, то нейронная сеть считается обученной.
В настоящее время круг решения задач, решаемых одной отдельно взятой нейронной сетью, довольно ограничен. Это связано с тем, что для каждого возможного применения нейросеть выбираются топология, алгоритмы и коэффициенты нейросети, наиболее подходящие для данной задачи, и они могут быть неприемлемы ни для какой другой [1].
Алгоритмы самоорганизации по классификации А.Г. Ивахненко представлены целым классом алгоритмов, реализующих механизмы направленных самоотборов [2]. Структура и базисные функции моделей алгоритма выбираются в зависимости от вида матрицы модели исследуемого процесса. Набор базисных функций ![]() , где
, где ![]() – нелинейные функции, может изменяться в зависимости от конкретных практических приложений. Каждой базисной функции ставится в соответствие двумерный вектор параметров
– нелинейные функции, может изменяться в зависимости от конкретных практических приложений. Каждой базисной функции ставится в соответствие двумерный вектор параметров ![]() , где a – амплитуда, f – частота, определяемых в процессе функционирования алгоритма. Искомая модель будет иметь вид:
, где a – амплитуда, f – частота, определяемых в процессе функционирования алгоритма. Искомая модель будет иметь вид:
![]() . (1)
. (1)
Алгоритм самоорганизации основывается на гипотезе селекции моделей. Первый шаг алгоритма состоит в идентификации базисных функций по заданному критерию. На следующих уровнях строится комбинация моделей предыдущего уровня, прошедших пороговый самоотбор по ансамблю критериев [10]. Однако методологической основой использования подхода самоорганизации для построения прогнозирующих моделей является допущение о том, что исчерпывающая информация, характеризующая динамику исследуемого объекта, содержится в измерениях (таблице наблюдений, выборке данных) и в ансамбле критериев селекции моделей. Измерительные выборки должны содержать достаточно полную информацию об объекте исследования, отражать современное состояние объекта, функционирующего в данных условиях. Если для построения модели использовать устаревшие или неполные информационные выборки, то модель получится неадекватной, и прогноз с использованием такой модели будет содеражть существенные погрешности.
Конструктивным подходом в решении задачи идентификации нелинейных систем управления является использование фильтрующей структуры в виде последовательности Вольтерра.
2. Реализация фильтра Вольтерра второго порядка для идентификации нелинейных систем управления
С теоретической точки зрения фильтр Вольтерра является привлекательным, так как он может взаимодействовать с общим классом нелинейных систем, в то время, как его выход остается линейным по отношению к различным системным ядрам высокого порядка или импульсным реакциям. Однако одной из главных причин достаточно редкого применения методики фильтрации Вольтерра на практике является значительная сложность, связанная с реализацией фильтров Вольтерра. Например, использование методики линеаризации, в которой фильтр Вольтерра рассматривается как линейный фильтр с мультиразмерным входным сигналом, приводит к серьезным вычислительным проблемам, связанным с увеличением количества операций при увеличении порядка фильтра. Таким образом, главной задачей является нахождение упрощений в разработке и реализации фильтра Вольтерра.
Особое внимание уделим фильтру Вольтерра 2-го порядка (ФВ2), который состоит из параллельной комбинации линейного и квадратичного фильтров, является прототипом нелинейного фильтра, при помощи которого можно улучшить характеристики линейного фильтра с относительно малой ошибкой вычисления. Определим ФВ2 как:
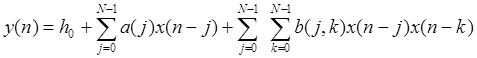 , (2)
, (2)
где {a(j)} и {b(j,k)} называются линейным и квадратичным весом соответственно, а N указывает длину фильтра (предполагается симметричность квадратичных весов фильтра, т.е. b(j,k) = b(k,j)) [8].
Требуется минимизировать средне-квадратическую ошибку (СКОШ) между основным сигналом s(n) и выходом фильтра y(n), т.е.
![]() . (3)
. (3)
Первым шагом в определении минимума СКОШ фильтра Вольтерра 2-го порядка является требование бездрейфового выхода фильтра. Другими словами, должно быть E[y(n)] = 0, т.к. основной сигнал имеет нулевое математическое ожидание. Тогда получается следующее соотношение между ![]() и b(j,k):
и b(j,k):
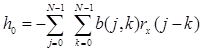 , (4)
, (4)
где ![]() обозначает автокорреляционную функцию x(n). Важно включение члена нулевого порядка
обозначает автокорреляционную функцию x(n). Важно включение члена нулевого порядка ![]() , так как без этого выход минимальной СКОШ ФВ2 не является обязательно бездрейфовым и ошибка будет иметь, следовательно, тенденцию к увеличению.
, так как без этого выход минимальной СКОШ ФВ2 не является обязательно бездрейфовым и ошибка будет иметь, следовательно, тенденцию к увеличению.
Следовательно, формула для определения ФВ2 будет выглядеть так:
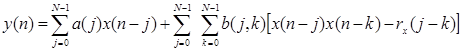 . (5)
. (5)
Следующий шаг – определение линейного и квадратичного весов фильтра, которые определяют минимум СКОШ. Для этого выведем простое решение для оптимального ФВ2 в предположении, что на входе фильтра белый гауссовый шум.
Формулу для определения ФВ2 можно переписать в матричном виде:
![]() {
{![]() }, (6)
}, (6)
где
![]() ,
,
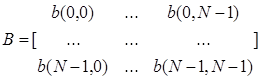 ,
,
а ![]() указывает на NxN матрицу от x(n), где
указывает на NxN матрицу от x(n), где ![]() – автокорреляционная функция входного сигнала x(n). А и В – операторы линейного и квадратичного фильтра соответственно [8].
– автокорреляционная функция входного сигнала x(n). А и В – операторы линейного и квадратичного фильтра соответственно [8].
Определим кросс-корреляционную rsx(j) и кросс-бикорреляционную tsx(j,k) функции между x(n) и s(n) следующим образом:
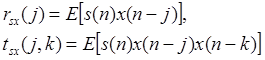 . (7)
. (7)
Поскольку предполагается, что s(n) и x(n) строго стационарны, то как rsx(j), так и tsx(j,k) являются независимыми от переменной n. Кроме того, кросс-бикорреляционная функция является симметричной: tsx(j,k) = tsx(k,j). Также можно определить кросс-корреляционную и крос-бикорреляционную функции в матричном виде:
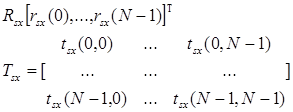 .
.
Итак, видно, что линейный и квадратичный операторы ФВ2 с минимальной СКОШ должны удовлетворять следующим математическим соотношениям:
![]() (8)
(8)
и
![]() . (9)
. (9)
После некоторых преобразований получается, что линейный и квадратичный операторы фильтра определяются следующим образом:
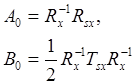 . (10)
. (10)
Из (10) видно, что линейный оператор оптимального ФВ2 – это то же самое, что и оптимальный линейный фильтр. Следовательно, можно сконструировать ФВ2 просто посредством добавления квадратичного фильтра параллельно созданному линейному фильтру без его изменения.
Таким образом, процедура реализации ФВ2 упрощается без существенной потери точности.
Выводы
Рассмотрены наиболее распространенные на современном этапе методы идентификации нелинейных систем. Выявлены их достоинства и недостатки. Для идентификации нелинейных систем выделен алгоритм фильтра Вольтерра второго порядка. Разработана компактная процедура реализации оптимального ФВ2, существенно упрощающая его применение. В дальнейшем распространение полученных результатов на фильтры Вольтерра более высоких порядков является интересным предметом исследования.
Рецензенты:
Пролетарский А.В., д.т.н., профессор, декан факультета «Информатика и системы управления», зав. кафедрой «Компьютерные системы и сети», МГТУ им. Н.Э. Баумана, г. Москва;
Неусыпин К.А., д.т.н., профессор, профессор кафедры «Системы автоматического управления», МГТУ им. Н.Э. Баумана», г. Москва.
Библиографическая ссылка
Цибизова Т.Ю. МЕТОДЫ ИДЕНТИФИКАЦИИ НЕЛИНЕЙНЫХ СИСТЕМ УПРАВЛЕНИЯ // Современные проблемы науки и образования. 2015. № 1-1. ;URL: https://science-education.ru/en/article/view?id=17910 (дата обращения: 01.07.2026).