



Введение
В настоящее время существует большое количество текстов, которые содержат неоднородные включения. Это студенческие и псевдонаучные работы, скомпилированные из разных источников, а также тексты, подвергшиеся существенному редактированию. Зачастую данные тексты выдаются как собственные, уникальные, написанные непосредственно самим автором. Поэтому возникают задачи отделения фрагментов, написанных самостоятельно, от скопированных [7] фрагментов, а также нахождения автора, или первоисточника [3]. Кроме того, существует задача поиска в литературном тексте фрагментов с разной эмоциональной окраской [2; 8].
Существующие современные системы, такие как системы обнаружения плагиата, существенно опираются на базы текстов. Если по каким-либо причинам текст, который использовался при создании, не вошёл в поисковые базы, то система может принять фрагмент данного текста как уникальный. Следовательно, методы, которые позволяют выявлять неоднородные фрагменты в тексте, и тем самым указывать на возможность плагиата без привязки к базам данных, являются актуальными и своевременными.
В данной работе предлагается алгоритм поиска фрагментов, имеющих отличную от основного текста синтагматику, характеризующуюся определённой последовательностью составляющих элементов – слов с частеречной принадлежностью. В основе алгоритма лежит статистика частоты встречаемости последовательностей частей речи, состоящих из трёх или четырёх слов.
В данной статье рассматривается непосредственно сам алгоритм нахождения неоднородных фрагментов на основе последовательностей частей речи, предложен один из способов выбора последовательностей для анализа, рассмотрены примеры, а также возможность применения данного алгоритма к атрибуции текстов. Работа выполняется при финансовой поддержке Программы стратегического развития ПетрГУ в рамках реализации комплекса мероприятий по развитию научно-исследовательской деятельности.
Алгоритм поиска неоднородности фрагмента текста
1. Разметка исходного текста.
С помощью какого-либо грамматического анализатора производится разметка исходного текста. В качестве такого анализатора можно взять морфологический анализатор mystem [5] от компании «Яндекс». В результате исходный текст будет представлять собой последовательность частей речи, разделённых знаками препинания, концами абзацев и т.п. Поиск неоднородных фрагментов можно производить как с учётом этих знаков, так и без их учёта.
2. Выбор размера фрагмента.
Размер фрагмента можно задавать количеством слов или предложений. Выбор размера зависит от цели исследования. В производимых экспериментах величина фрагмента изменялась от одного до пятнадцати предложений.
3. Выбор признаков.
Для проведения исследования необходимо определиться с выбором исследуемой последовательности частей речи, которую в дальнейшем будем называть признаком. Среди множества вариантов последовательностей частей речи следует выбрать ту, которая обладает наибольшей информативностью.
Существует несколько способов выбора наиболее информативных признаков [1]. В качестве исследуемого признака можно выбрать тот, у которого статистика χ2 имеет максимальную дисперсию. Для этого следует рассмотреть всевозможные наборы признаков (различные варианты последовательностей частей речи), исследуемый текст разбить на фрагменты. Для каждого выбранного признака и каждого фрагмента необходимо найти статистику χ2 (способ вычисления статистики описан в следующем пункте), на основе которой высчитать дисперсию. В качестве исследуемого признака можно взять признак с максимальной дисперсией [1].
4. Вычисление статистики χ2.
Для исследуемого фрагмента текста нужно сосчитать, сколько раз выбранная последовательность слов встречается в данном фрагменте и сколько в остальной части текста. Обозначим: p' – число выбранных последовательностей, p – общее число последовательностей во фрагменте, q – общее число последовательностей в оставшемся тексте, q' – число выбранных последовательностей в оставшемся тексте. Тогда статистика χ2 имеет вид [6]:
![]()
где ![]() .
.
5. Поиск неоднородных фрагментов.
Исходный текст необходимо разбить на всевозможные фрагменты. Для каждого фрагмента вычислить статистику χ2 (аналогично предыдущему пункту). Максимальное значение данной статистики будет соответствовать неоднородным фрагментам. При этом если значение превысит некоторое критическое значение, то отличие данного фрагмента от остальных будет статистически значимым с вероятностью P.
Пример выявления наиболее информативных признаков
Алгоритм поиска неоднородного фрагмента текста апробирован на разных текстах. В качестве примера приведем ниже выявление наиболее информативных признаков для произведения Ф.М. Достоевского «Дворянин». Рассмотрим все возможные фрагменты, состоящие из 5 предложений. Для каждого фрагмента и для каждой последовательности из четырёх частей речи была вычислена статистика χ2. Для каждого признака подсчитана дисперсия. Часть результатов эксперимента, отсортированная по убыванию значения дисперсии, приведена в табл. 1. Максимальное значение дисперсии 142,96 соответствует четвёрке «Глагол – Существительное – Союз – Существительное». Этот признак для данного текста наиболее информативен.
Таблица 1 – Значения статистики χ2 для различных признаков и фрагментов в произведении Ф.М. Достоевского «Дворянин»
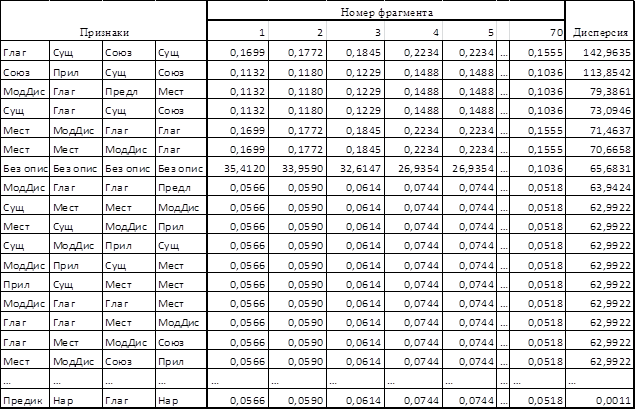
Аналогичным образом в том же тексте был проведён эксперимент по выявлению наиболее информативных троек. Тройкой с наибольшей дисперсией стала «Глагол – Причастие – Существительное».
Примеры неоднородных фрагментов текстов
В результате применения алгоритма был найден фрагмент неоднородности. Далее приведен кусок текста из произведения Ф.М. Достоевского «Дворянин», в котором найденный фрагмент выделен курсивом.
Въ 45 № «Современной Лѣтописи Русскаго Вѣстника», за подписью г. К. Буха, напечатано было любопытное извѣстіе объ одномъ дворянинѣ, который хотѣлъ перечислиться въ государственные крестьяне. Въ мензелинскомъ уѣздѣ оренбургской губерніи, въ селѣ Покровскомъ, по–народному Новая–Мазина, живетъ неслужащій дворянинъ симбирской губерніи Петръ Порфирьевичъ Мясоѣдовъ. Женившись на дочери государственнаго крестьянина того же села, Максима Андреева, онъ подалъ просьбу о причисленіи его въ государственные крестьяне, въ семейство тестя. Присутственное мѣсто, въ которое поступила его просьба, отказало ему, потому что по 619 статьѣ IX т. св. зак. гражд., изд. 1857 года, въ сельское состояніе могутъ быть причислены дѣти личныхъ дворянъ и приказнослужителей, не имѣющихъ оберъ–офицерскихъ чиновъ, а г. Мясоѣдовъ происходитъ отъ потомственной дворянской фамиліи. Отказъ этотъ въ точности соотвѣтствуетъ приведенной статьѣ закона. Но справедливо ли — спрашиваетъ далѣе авторъ — лишать человѣка возможности вступать въ ту среду, въ которой, по его понятіямъ и связямъ, онъ для себя находитъ болѣе выгодъ и удобствъ? Далѣе авторъ старается доказать, что не можетъ быть вреда отъ перечисленія человѣка, имѣющаго права дворянина, въ сословіе государственныхъ крестьянъ, и что не можетъ быть пользы отъ насильственнаго удержанія въ сословіи лица, которое отстало отъ того сословія и привычками, и образомъ жизни.
На обращеніе г. Буха къ юристамъ, на вызовъ его обсудить этотъ вопросъ, юристъ отыскался въ 49 № той же «Современной Лѣтописи Русскаго Вѣстника». Этотъ достопочтенный журналъ, соболѣзнующій о безжизненности нашей умственной среды, нашолъ возможнымъ и на этотъ новый вопросъ г. Буха отвѣтить отрицательно, отказомъ.
Приведем неоднородный фрагмент из 5 предложений этого же текста для четвёрок (признак «Глагол – Существительное – Союз – Существительное»):
Встрѣчаются напримѣръ на большой дорогѣ между Владиміромъ и Нижнимъ два обоза, на постояломъ дворѣ. Люди владимірскаго обоза распрашиваютъ, нѣтъ ли здѣсь въ обозѣ кого изъ новоторжскаго уѣзда тверской губерніи? Оказывается, что есть, и к тому же почти изъ той самой деревни, какая нужна. Выходитъ, что въ обозѣ дорогою изъ Москвы умеръ мужикъ, которому принадлежала тройка и товаръ. Товарищи продали все это во Владимірѣ, выручили 600 рублей, и зная, что у покойника на селѣ остался отецъ и семья, ищутъ съ кѣмъ бы послать деньги. И встрѣчный мужикъ вѣшаетъ деньги къ себѣ на крестъ и черезъ полгода, съѣздивъ еще изъ Москвы въ Харьковъ и добравшись наконецъ до родного села, приноситъ семьѣ и деньги, и вѣсть о томъ, что Кирюха померъ, не доѣзжая какихъ–нибудь пятидесяти верстъ до Владиміра. «Такъ, сердечный, и не доѣхалъ; а до Владиміра всего одна какая–нибудь упряжка осталась, а много двѣ, такъ и померъ, не доѣхалъ». Разсказываются сотни подобныхъ примѣровъ. Напримѣръ еще на постояломъ дворѣ одинъ торговецъ, изъ крестьянъ, провожаетъ другого въ деревню, и проводы справляются обильнымъ чаепитіемъ. «Поклонись ты батюшкѣ, да въ Москвѣ безпремѣнно купи женѣ платокъ въ два съ полтиной; да вотъ, какъ будешь въ Ярославлѣ, зайди къ Никанору Ѳедотову, знаешь? отдай ему вотъ тысячу двѣсти, чтобъ безпремѣнно по–прошлогоднему холстовъ мнѣ выслалъ, да чтобъ тѣхъ самыхъ рукъ холсты были; ты это ему накажи строго–настрого, а то онъ вѣдь мужикъ плутъ, пришлетъ пожалуй не тѣхъ». И отъѣзжающій суетъ за сапогъ деньги, завернутыя въ сальную бумагу, и деньги не пропадаютъ. И еще сотни подобныхъ примѣровъ разсказываются удивленными лицами верхняго лагеря, и въ тоже время тысячи есть примѣровъ крайней недобросовѣстности, совершеннаго отсутствія самыхъ элементарныхъ понятій о чести въ поступкахъ лицъ нижняго лагеря относительно лицъ верхняго.
Отчего же это? Можетъ ли это понять, сумѣетъ ли догадаться г. Ростиславовъ? Причины, заставившія г. Мясоѣдова желать перечисляться въ крестьяне — чисто–психологическія, о которыхъ не можетъ быть рѣчи въ Сводѣ законовъ.
В ходе проведённых экспериментов для различных текстов было обнаружено, что наиболее информативными, с точки зрения максимальной дисперсии, являлись последовательности: для трёх частей речи «Местоимение – Наречие – Союз», «Глагол – Наречие – Союз» и «Предлог – Числительное – Существительное». Для последовательностей из четырёх частей речи наиболее информативными оказались: «Предлог – Прилагательное – Существительное – Глагол», «Существительное – Существительное – Существительное – Глагол» и «Предлог – Местоимение – Местоимение – Наречие».
Применение алгоритма к атрибуции текстов
Заметим, что алгоритм выявления неоднородных фрагментов можно использовать и для решения задачи атрибуции текстов. Рассмотрим следующую задачу. Имеется n текстов, которые будем считать однородными. В качестве таких текстов можно брать произведения, принадлежащие одному автору. Ставится задача определения степени близости неизвестного текста к этой группе. Решение данной задачи разобьём на несколько этапов. На первом этапе выбирается признак, затем по очереди выбирается один текст из группы однородных текстов. Оставшиеся произведения объединяются в один большой текст. Для каждого текста вычисляется статистика![]() . Вычисление производится аналогично пункту 4 алгоритма поиска неоднородности для фрагмента. В качестве фрагмента будет выбранный текст. В качестве оставшегося текста будет выступать полученный объединенный. Будем обозначать значения статистик через
. Вычисление производится аналогично пункту 4 алгоритма поиска неоднородности для фрагмента. В качестве фрагмента будет выбранный текст. В качестве оставшегося текста будет выступать полученный объединенный. Будем обозначать значения статистик через ![]() ,
, ![]() …,
…,![]() . На следующем этапе выбирается анализируемый текст, а в качестве второго берётся текст, полученный в результате объединения всех однородных. Для анализируемого текста вычисляется статистика
. На следующем этапе выбирается анализируемый текст, а в качестве второго берётся текст, полученный в результате объединения всех однородных. Для анализируемого текста вычисляется статистика![]() . Обозначим её через
. Обозначим её через![]() . Если выполняется неравенство
. Если выполняется неравенство![]() , то искомый текст будет близок к данной группе по выбранному признаку. Близость текста к выбранной группе автоматически не означает решение задачи атрибуции. Для этого требуется критическая оценка полученного результата специалистом.
, то искомый текст будет близок к данной группе по выбранному признаку. Близость текста к выбранной группе автоматически не означает решение задачи атрибуции. Для этого требуется критическая оценка полученного результата специалистом.
Для проверки работоспособности алгоритма в качестве однородных текстов использовались произведения, принадлежащие Ф.М. Достоевскому [4]. В качестве неоднородных текстов – произведения В.И. Даля, М.И. Владиславлева и А.А. Григорьева.
Для последовательностей из трёх частей речи (триад) «Местоимение – Наречие – Союз», «Существительное – Наречие – Модально-дискуссивное слово», «Глагол – Наречие – Существительное», «Предлог – Наречие – Существительное» статистика ![]() для текстов Достоевского была меньше, чем для остальных текстов. Исключение составил текст «Загадки». Это может быть связано с тем, что размер данного текста был значительно меньше размеров остальных. Результаты эксперимента представлены в табл. 2. В колонке «Достоевский» выделены максимальные значения статистик
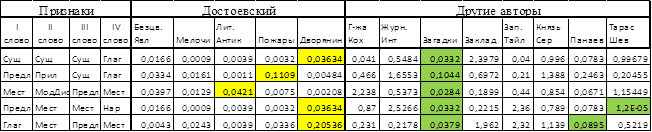
для текстов Достоевского была меньше, чем для остальных текстов. Исключение составил текст «Загадки». Это может быть связано с тем, что размер данного текста был значительно меньше размеров остальных. Результаты эксперимента представлены в табл. 2. В колонке «Достоевский» выделены максимальные значения статистик![]() среди текстов Достоевского. А в колонке «Другие авторы» – значения, которые оказались меньше максимального значения из колонки «Достоевский». Для последовательностей из четырёх частей речи (четвёрки) такими последовательностями оказались: «Существительное – Существительное – Существительное – Глагол», «Предлог – Прилагательное – Существительное – Глагол» и «Местоимение – Модальное-дискуссивное слово – Предлог – Местоимение». Исключение составил всё тот же текст «Загадки». Результаты представлены в табл. 3.
среди текстов Достоевского. А в колонке «Другие авторы» – значения, которые оказались меньше максимального значения из колонки «Достоевский». Для последовательностей из четырёх частей речи (четвёрки) такими последовательностями оказались: «Существительное – Существительное – Существительное – Глагол», «Предлог – Прилагательное – Существительное – Глагол» и «Местоимение – Модальное-дискуссивное слово – Предлог – Местоимение». Исключение составил всё тот же текст «Загадки». Результаты представлены в табл. 3.
Таблица 2 – Сравнение текстов Достоевского с другими авторами на основании триад
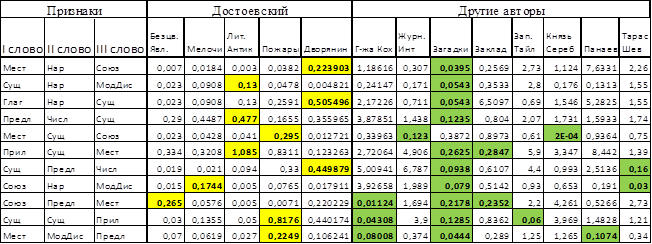
Таблица 3 – Сравнение текстов Ф.М. Достоевского с другими авторами на основании четвёрок
При использовании последовательностей без учёта границ предложений для последовательностей «Предлог – Прилагательное – Существительное – Глагол» и «Существительное – Прилагательное – Существительное – Модально-дискуссивное слово» максимальное значение статистики ![]() для текстов Достоевского было меньше, чем для остальных текстов (табл. 4).
для текстов Достоевского было меньше, чем для остальных текстов (табл. 4).
Таблица 4 – Сравнение текстов Ф.М. Достоевского с другими авторами на основании четвёрок без учёта границ предложений и абзацев

Заключение
Проведённые эксперименты показали, что с помощью описанного алгоритма можно выделить из текста фрагменты неоднородности, имеющие разные частоты встречаемости выбранной последовательности частей речи. Найденные фрагменты могут служить подсказкой для специалиста-филолога о том, что здесь может быть текст другого автора. Таким образом, данный алгоритм будет полезен при обнаружении плагиата: анализ может производиться не по всему тексту, а лишь по выделенным фрагментам неоднородности, что сократит размерность задачи. В дальнейшем планируется провести исследования по выявлению неоднородных фрагментов при условии выбора в качестве признаков линейной комбинации различных последовательностей.
Рецензенты:
Питухин Евгений Александрович, доктор технических наук, профессор кафедры прикладной математики и кибернетики, ФГБОУ ВПО «Петрозаводский государственный университет», г. Петрозаводск.
Печников Андрей Анатольевич, доктор технических наук, ведущий научный сотрудник лаборатории телекоммуникационных систем, ФГБУН «Институт прикладных математических исследований» Карельского научного центра Российской академии наук (ИПМИ КарНЦ РАН), г. Петрозаводск.
Библиографическая ссылка
Седов А.В., Рогов А.А. АНАЛИЗ НЕОДНОРОДНОСТЕЙ В ТЕКСТЕ НА ОСНОВЕ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ЧАСТЕЙ РЕЧИ // Современные проблемы науки и образования. 2013. № 1. ;URL: https://science-education.ru/ru/article/view?id=8339 (дата обращения: 22.06.2026).