



Ключевым этапом ТЗ является аналитическая обработка информации о локализации участков, полученной с помощью навигационных систем (GPS, GLONASS), данных агрохимического и агрофизического обследования почв, истории урожайности. Анализ данных в ТЗ позволяет обнаруживать зависимости, которые «объясняют» характер влияния тех или иных агрохимических и агрофизических характеристик на урожайность. Знание таких зависимостей позволяет принимать решения о целесообразности проведения мероприятий, направленных на повышение урожайности, их объем и локализацию.
Важную роль в анализе сельскохозяйственных данных с целью реализации ТЗ является моделирование урожайности [2]. Построенные модели позволяют не только оценивать ее потенциальный уровень для площадей с определенными агрохимическими параметрами, но и исследовать степень и характер влияния того или иного параметра на урожайность. Например, если модель отражает зависимость урожайности от содержания в почве подвижного азота, то с ее помощью можно оценить количество удобрений, которое требуется внести для получения желаемой урожайности. Кроме этого, такая модель позволит оценить ожидаемый экономический эффект, т.е. соотнести затраты на внесение удобрений и дополнительную прибыль от увеличения урожайности, и сделать вывод о целесообразности проведения данного вида агрохимических мероприятий.
Построение моделей урожайности является достаточно сложной задачей, поскольку требует учета большого количества агрохимических и агрофизических факторов, которые характеризуются высокой степенью взаимных связей, обычно сложных и нелинейных. Например, известно, что высокая кислотность почв не только сама по себе негативно влияет на рост растений, но и ухудшает усвояемость ими содержащихся в почве макроэлементов (азота, фосфора, калия). Поэтому внесение одного и того же количества удобрений на участки с различной кислотностью даст совершенно различный результат.
Сложность и нелинейность зависимостей между признаками часто делает применение классических методов прикладной статистики для построения моделей урожайности малоэффективным, а результаты моделирования трудно интерпретируемыми. Кроме этого, сельхозпредприятия не всегда содержат в своем штате аналитиков, имеющих соответствующую математическую подготовку. В этой связи практический интерес представляет разработка методик применения различных эвристических методов, которые, хотя и не являются полностью математически обоснованными, позволяют получить приемлемое решение в большинстве практически значимых случаев. В данной работе рассматривается метод моделирования урожайности на основе данных агрохимического обследования почв с помощью технологии, известной в зарубежной литературе как weight of evidence (WoE), что можно перевести как совокупность доказательств или вес доказательства [6]. Изначально метод использовался для поддержки принятия решений в кредитном скоринге, позже нашел применение в медицинской диагностике, поиске полезных ископаемых, выявлении мошенничеств и других областях. Рассмотрим ведомость агрохимического обследования почв (яровой ячмень [2]), фрагмент которой представлен на рис. 1.
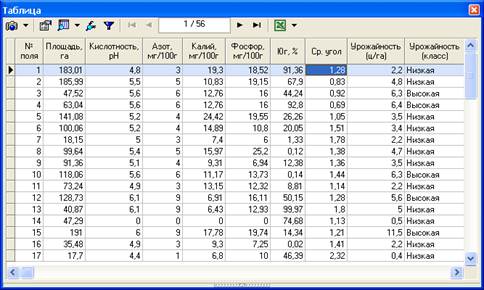
Рис. 1. Фрагмент ведомости агрохимического обследования почв.
Она содержит следующие показатели:
- № поля - уникальный идентификатор записи;
- площадь - площадь поля в гектарах;
- кислотность - средняя кислотность почв, pH;
- азот - среднее содержание подвижного азота в почве, мг/100 г;
- калий - среднее содержание подвижного калия в почве, мг/100 г;
- фосфор - среднее содержание фосфора в почве, (мг/100 г);
- юг - процент пашни с уклоном к югу;
- средний угол - средний угол уклона, градусов;
- урожайность - наблюдаемая средняя урожайность, ц/га;
- урожайность (класс) - бинарная переменная, которая принимает значение «Высокая» для урожайности больше 6 ц/га и «Низкая» - в противном случае.
На основе этих данных можно построить два типа моделей - численного предсказания и классификации. Для обеих моделей в качестве независимых переменных используются площадь, кислотность, калий, фосфор, юг и средний угол. Для модели численного предсказания выходной переменной будет урожайность числом, а для классификационной - класс урожайности. Во многих практических приложениях нет необходимости знания точных значений целевой переменной. Для принятия решения достаточно знать общий характер ее зависимости от входных переменных. Кроме этого, классификационные модели более удобны для интерпретации, чем численные, поскольку могут генерировать правила, формируемые на естественном языке [3].
Рассмотрим каждое наблюдение набора данных как эксперимент, исходом которого будет класс урожайности (высокая/низкая). Ведомость агрохимического обследования содержит 41 поле с низкой урожайностью и 15 - с высокой. Предположим, что целью классификации является обнаружение полей с высокой урожайностью для поддержки принятия решений о целесообразности их засева либо планирования соответствующих агротехнологических мероприятий. Тогда появление в наблюдении значения переменной класса «Высокая» будем называть событием, а значения «Низкая» - не-событием.
Произведем квантование диапазона значений каждой независимой переменной на заданное число интервалов. Рассмотрим переменную «Азот». Ее минимальное наблюдаемое значение составляет 2, а максимальное - 9. Разобьем данный диапазон на 4 интервала, каждый из которых соответствует изменению переменной на 2, т.е. 2-3, 4-5, 6-7 и 8-9. Для каждого интервала подсчитаем количество событий ![]() и не-событий
и не-событий ![]() для наблюдений, в которых значение переменной «Азот» попало в соответствующий интервал. Затем рассчитаем коэффициенты, называемые весами доказательств, по формуле [4]:
для наблюдений, в которых значение переменной «Азот» попало в соответствующий интервал. Затем рассчитаем коэффициенты, называемые весами доказательств, по формуле [4]:
![]() , (1)
, (1)
где i - номер интервала, P=15 общее число положительных исходов в наборе данных, N=41 - общее число отрицательных исходов. Результаты расчетов представлены в таблице 1.
Таблица 1 - Результаты формирования интервалов для вычисления коэффициентов WoE для содержания азота
|
№ интервала |
Интервал |
Pi |
Ni |
Вес интервала |
WoE |
|
1 |
2-3 |
0 |
18 |
0,32 |
3,89 |
|
2 |
4-5 |
0 |
16 |
0,29 |
3,78 |
|
3 |
6-7 |
6 |
3 |
0,16 |
-1,71 |
|
4 |
8-9 |
9 |
4 |
0,23 |
-2,19 |
Вес интервала - отношение числа наблюдений, попавших в интервал, к общему числу наблюдений. Чтобы избавиться от 0 в знаменателе выражения под логарифмом, определим 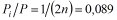 , где
, где ![]() - общее число наблюдений. Такая подстройка удобна тем, что ее значение всегда больше нуля и гарантированно меньше любого возможного
- общее число наблюдений. Такая подстройка удобна тем, что ее значение всегда больше нуля и гарантированно меньше любого возможного ![]() (или
(или ![]() , если аналогичную подстройку проводить для не-событий).
, если аналогичную подстройку проводить для не-событий).
Проинтерпретируем полученные результаты. Интервалы № 1 и 2, которые не содержат положительных исходов (т.е. наблюдений с высокой урожайностью), соответствуют низкому уровню содержания азота в почве. Интервалы № 3 и 4, соответствующие высокому содержанию азота, содержат большую часть наблюдений с высокой урожайностью. При этом коэффициенты ![]() для интервалов № 1 и 2 являются положительными, а для интервалов № 3 и 4 - отрицательными. Из формулы (1) видно, что если относительная доля отрицательных исходов (не-событий) больше, чем положительных (событий), то значение под знаком логарифма больше 1 и коэффициент
для интервалов № 1 и 2 являются положительными, а для интервалов № 3 и 4 - отрицательными. Из формулы (1) видно, что если относительная доля отрицательных исходов (не-событий) больше, чем положительных (событий), то значение под знаком логарифма больше 1 и коэффициент ![]() оказывается положительным, а в противном случае - отрицательным. Следовательно,
оказывается положительным, а в противном случае - отрицательным. Следовательно, ![]() указывает на большую вероятность появления положительного исхода, а
указывает на большую вероятность появления положительного исхода, а ![]() - отрицательного.
- отрицательного.
Таким образом, если новое наблюдение, т.е. земельный участок с известными агрохимическими параметрами, но с неизвестной урожайностью, имеет содержание азота в почве 2-5 мг/100 г, то модель классифицирует урожайность как низкую, а если 6-9, то как высокую. Модель показала, что с увеличением содержания азота урожайность растет, что согласуется с теорией растениеводства.
Следует, однако, учитывать, что урожайность зависит не только от содержания азота, но и от других агрохимических показателей, представленных в наборе данных на рис. 1. Для каждого из них можно провести аналогичные вычисления и определить характер его влияния на урожайность. Открытым остается вопрос о силе этого влияния, т.е. значимости каждого признака с точки зрения классификации. Для оценки такой значимости вводится показатель, называемый информационным индексом [4]:
![]() . (2)
. (2)
Информационный индекс отражает степень связи признака и бинарной выходной переменной. Для данных из таблицы 1 его значение составит:
![]() .
.
С помощью значения ![]() можно оценить значимость (предсказательную силу) переменной для бинарной классификации:
можно оценить значимость (предсказательную силу) переменной для бинарной классификации: ![]() - отсутствует;
- отсутствует; ![]() - низкая;
- низкая; ![]() - средняя;
- средняя; 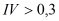 - высокая, выше 3 - очень высокая. Таким образом, можно сделать вывод о высокой значимости влияния содержания азота в почве на урожайноcть.
- высокая, выше 3 - очень высокая. Таким образом, можно сделать вывод о высокой значимости влияния содержания азота в почве на урожайноcть.
Средством визуализации результатов WoE-анализа являются диаграммы, где для каждого интервала значение коэффициента WoE отражается в виде столбца соответствующей высоты. Например, для азота WoE-диаграмма будет иметь вид, представленный на рис. 2. Интерпретация WoE-диаграмм проста: для интервалов значений входного признака с коэффициентами WoE<0 появление положительных исходов классификации (событий) более вероятно, а вероятность пропорциональна значению коэффициента.
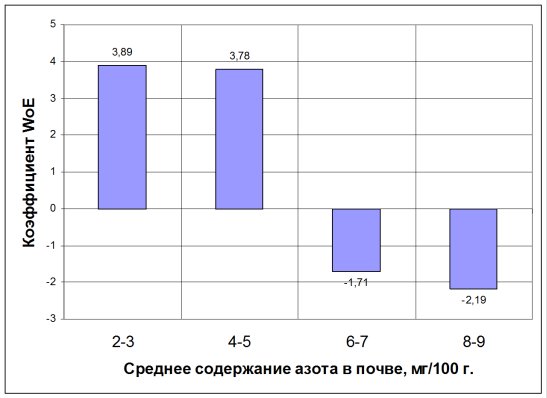
Рис. 2. Диаграмма WoE для содержания азота в почве.
В частности, диаграмма на рис. 2 однозначно указывает на то,что повышенное содержание азота в почве способствует увеличению урожайности.
Очевидной проблемой метода, обуславливающей его эвристическую сущность, является отсутствие формально обоснованных рекомендаций по выбору числа интервалов для вычисления коэффициентов WoE и информационного индекса. В рассмотренном выше примере разделение диапазона изменения содержания азота на 4 равных интервала, очевидно, не является оптимальным. Действительно, до значения 6 мг/100 г встречаются только не-события, поэтому интервалы № 1 и 2 можно объединить в один с ![]() . Тогда информационный индекс для признака составит
. Тогда информационный индекс для признака составит ![]() . Он несколько снизился, но по-прежнему указывает на высокую значимость признака, хотя модель существенно упростилась.
. Он несколько снизился, но по-прежнему указывает на высокую значимость признака, хотя модель существенно упростилась.
На практике можно использовать два способа разбиения признаков на WoE-интервалы: 1) так, чтобы в каждый интервал попадало примерно одинаковое число наблюдений (событий и не-событий); 2) так, чтобы максимизировать информационный индекс. Первый способ является логически более прозрачным для пользователя, интервалы проще интерпретируются. При выборе второго способа, поскольку значение информационного индекса возрастает с увеличением числа интервалов, алгоритм будет стремиться максимизировать его, и если не ввести ограничений, то каждый интервал будет сформирован для отдельного значения. Ограничением является вес интервала - процент попавших в него наблюдений относительно их общего числа. Тогда разбиение на интервалы закончится, как только будет получен интервал с весом ниже заданного (скажем, 10%). Таким образом, для второго способа, варьируя минимальный вес интервала, аналитик может добиваться построения наиболее «адекватной», с его точки зрения, WoE-модели.
Еще одним важным вопросом является выбор числа интервалов. Можно использовать два основных подхода.
1. Максимизация информационного индекса. Как правило, в результате получается очень большое число интервалов (несколько десятков), что влечет три недостатка:
а) ухудшается интерпретируемость модели: WoE-диаграмма будет содержать большое количество столбцов для коэффициентов с различными знаками;
б) модель окажется «переобученной», т.е. слишком точно «подогнанной» под исходные данные. Это приведет к ухудшению ее обобщающей способности при работе с новыми наблюдениями: даже небольшие вариации исходных данных могут привести к изменению класса наблюдения и ошибочным выводам;
в) большое число интервалов в соответствии с формулой (2) приведет к росту информационного индекса и завышенной оценке значимости признака. Данное явление в зарубежной литературе известно под синтетическим термином overprediction, который пока не имеет устоявшегося перевода на русский язык.
2. Субъективные представления аналитика. Аналитик может выбрать число интервалов, исходя из представлений о том, насколько значительным должно быть изменение признака, чтобы повлиять на результаты классификации объекта. Например, в кредитном скоринге одним из признаков для оценки кредитоспособности клиента является возраст. Очевидно, что за 1-2 года социальный статус и доход клиента в большинстве случаев значительно не меняется, а вот за 10-15 лет это вполне вероятно. Следовательно, весь наблюдаемый диапазон возраста, скажем, с 18 до 75, следует разбить на интервалы по 10 лет, что позволит получить 5-6 интервалов. Аналогичным образом содержание макроэлементов в почве также классифицируется на очень низкую, низкую, среднюю, повышенную, высокую и очень высокую, а кислотность почв на очень сильнокислую, среднекислую, слабокислую, нейтральную и щелочную. Поэтому для соответствующих признаков агрохимической ведомости на рис. 1 при проведении WoE-анализа можно использовать 6 интервалов и ассоциировать с перечисленными классами. Это сделает модель более интерпретируемой, а информационный индекс реально отражающим вклад признака в классифицирующую способность модели.
Таким образом, построение WoE-модели может потребовать многочисленных экспериментов с целью подбора числа интервалов и выбора способа их формирования, минимального веса интервалов. Поэтому «ручная» реализация WoE-анализа, например в электронных таблицах, может оказаться весьма трудоемкой, особенно на больших массивах данных. В настоящее время WoE-анализ включается как в предметно-ориентированные программные средства анализа данных, так и в универсальные аналитические платформы (например, SAS Enterprise Miner). Единственной отечественной разработкой, в которой доступен алгоритм реализации WoE-анализа и эффективная визуализация его результатов, является аналитическая платформа Deductor Enterprise компании Basegroup Labs (http://www.basegroup.ru/) [4].
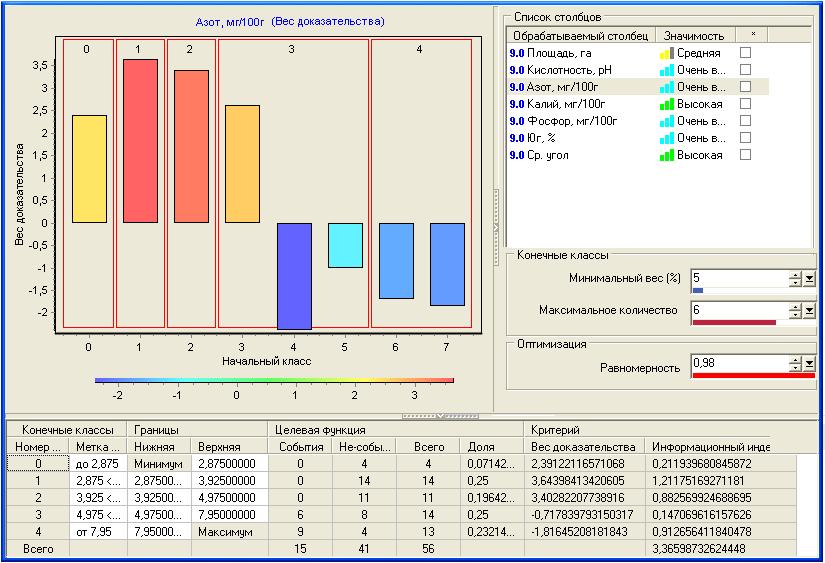
Рис. 2. Окно реализации WoE-анализа аналитической платформы Deductor.
Общий вид окна обработчика, реализующего WoE-анализ в аналитической платформе Deductor, представлен на рис. 2. В нем содержится список переменных, на которых строилась модель; диаграмма, где отображаются коэффициенты WoE для выделенной переменной; таблица, содержащая границы интервалов, количество наблюдений (событий и не-событий), попавших в каждый интервал, вес и WoE-коэффициент интервала, а также значение информационного индекса. Обработчик является интерактивным: изменяя минимальный вес и выбирая количество интервалов, аналитик подбирает наиболее подходящий вид модели. Критерием при этом может служить субъективное представление исследователя, максимальная значимость всех признаков и интерпретируемость WoE-диаграммы в смысле отражения зависимости класса урожайности от агрохимических показателей.
Приведем обобщенные результаты анализа ведомости агрохимического обследования почв в таблице 2 для следующих параметров: минимальный вес класса - 5%, число интервалов - 6 (для всех переменных), метод разбиения на интервалы - равномерный.
Таблица 2 - Результаты WoE-анализа для ведомости агрохимического обследования
|
Показатель |
WoE средний |
Коэф. корреляции |
Информационный индекс |
Значимость |
|
Площадь участка, га |
-0,082 |
0,009 |
0,297 |
Средняя |
|
Кислотность, pH |
3,000 |
0,638 |
4,637 |
Оч. высокая |
|
Азот, мг/100 г |
5,700 |
0,671 |
4,963 |
Оч. высокая |
|
Калий, мг/100 г |
0,152 |
0,207 |
0,664 |
Высокая |
|
Фосфор, мг/100 г |
3,800 |
0,481 |
3,928 |
Оч. высокая |
|
Уклон к югу, % |
0,132 |
0,097 |
0,066 |
Низкая |
|
Средний угол, ° |
0,092 |
0,188 |
0,293 |
Средняя |
По таблице можно сделать следующие выводы. Высокой и очень высокой значимостью для урожайности обладают кислотность, содержание азота, калия и фосфора, т.е. агрохимические параметры почвы, непосредственно влияющие на рост растений. Агрофизические факторы, такие как доля пашни с уклоном к югу и средний угол уклона, показывают среднюю и низкую значимость, что позволяет исключить их из модели.
Для сравнения в таблице 2 представлен коэффициент корреляции Пирсона для каждой входной переменной и урожайности. Он отражает линейные зависимости между величинами, поэтому при наличии нелинейных зависимостей не позволяет делать корректные выводы о значимости связи между ними. Кроме этого, коэффициент корреляции ограничен диапазоном от -1 до 1, что не всегда позволяет четко разделить значимые и не значимые факторы. Например, коэффициент корреляции с урожайностью для переменных калий (0,207) и средний угол (0,188) очень близки. В то же время информационные индексы, равные соответственно 0.664 и 0.293, различаются более чем в два раза. Благодаря нелинейной обработке при вычислении коэффициентов WoE с помощью логарифмической функции различия в значимости переменных являются более выраженными и легко обнаруживаются.
И, наконец, средние значения коэффициента WoE, вычисленные по всем интервалам признака, позволяют увидеть, на изменение каких агрохимических параметров урожайность будет реагировать наиболее сильно. В нашем случае это содержание азота, кислотность и содержание фосфора. Поэтому агрохимические мероприятия, направленные на увеличение содержания данных элементов в почве, являются наиболее перспективными с точки зрения повышения урожайности.
Заключение. Таким образом, в статье рассмотрен метод моделирования урожайности зерновых (на примере ярового ячменя) по данным агрохимического обследования почв на множестве земельных участков с различной площадью на основе WoE-анализа. WoE-анализ представляет собой простой в использовании, понимании и интерпретации метод моделирования многомерных данных с целью обнаружения связей между бинарной выходной переменной класса (урожайность) и набором входных переменных (агрохимических показателей), на основе распределения относительных частот появления положительных и отрицательных исходов по диапазону изменения входной величины. Он позволяет обнаруживать значимость влияния признака на переменную класса и исключать наименее значимые признаки, сокращая размерность исходных данных, упрощая их интерпретируемость и дальнейшую обработку.
В процессе моделирования урожайности на основе ведомости агрохимического обследования почв было обнаружено, что наибольшее влияние на урожайность оказывают содержание азота, фосфора и кислотность почв, и в несколько меньшей степени - содержание калия. Именно регулирование содержания данных веществ обеспечивает основной потенциал повышения эффективности агробизнеса в рамках концепции точного земледелия.
Рецензенты
- Солдак Юрий Максимович, доктор экономических наук, профессор кафедры экономики, менеджмента и организации производства ФГБОУ «Рязанский государственный радиотехнический университет», г. Рязань.
- Текучев Владимир Васильевич, доктор экономических наук, профессор, заведующий кафедрой экономической кибернетики ФГБОУ «Рязанский государственный агротехнологический университет им. П.А. Костычева», г. Рязань.
Библиографическая ссылка
Васильев Е.П., Орешков В.И. МОДЕЛИРОВАНИЕ УРОЖАЙНОСТИ ЗЕРНОВЫХ С ИСПОЛЬЗОВАНИЕМ МЕТОДА СОВОКУПНОСТИ ДОКАЗАТЕЛЬСТВ В РАМКАХ КОНЦЕПЦИИ ТОЧНОГО ЗЕМЛЕДЕЛИЯ // Современные проблемы науки и образования. 2012. № 5. ;URL: https://science-education.ru/ru/article/view?id=6972 (дата обращения: 01.07.2026).