



Введение
Рост популярности web-служб предоставил в распоряжение пользователей различные виды информации: текст, изображение, видео, аудио, каждый из которых, довольно однороден. Вследствие этой особенности, а также информационных потребностей пользователя, информация, которая возвращается к пользователю, представлена в виде отдельных документов, что не всегда удовлетворяет ожиданиям пользователя. В действительности, доступ к информации посредством Интернет-приложений стал обычным явлением, однако, не всегда пользователи точно и формализовано описывает свои запросы на получение информации, а, приложения дают ответ сообразно ожиданиям пользователей. Такая ситуация возникает вследствие наложения многих факторов: недостаточная выразительность языков исполнения запросов к данным, наличие многих источников информации с перекрестными ссылками, сверхбольшие объемы информации, временная недоступность, либо, перегруженность при доступе к базам данных (БД) и другие факторы. В целом, с точки зрения современных БД хранить информацию под воздействием перечисленных факторов можно, или, применяя избыточность (количественную, пространственную), или, найти подходы к описанию явления в слабоструктурированном виде. В связи с этим, развитии направлений теории БД одним из актуальных вопросов сейчас является улучшение моделей извлечения информации, путем поиска новых мер подобия и новых подходов в работе со слабоструктурированными данными. Это позволит принимать во внимание содержание и структуру слабоструктурированных документов для повышения точности результатов в соответствии с запросами пользователей Интернет-приложений, использующих БД.
Слабоструктурированные данные: реализация БД и измерение информационного подобия
Слабоструктурированные данные [6] являются формой организации данных, при которой структура документа не может быть задана заранее, а БД, хранящая такие документы допускает недоопределенности в схеме описания, а также может изменяться в течении эксплуатации. Эта форма данных содержит теги и другие маркеры для отделения семантических элементов и для обеспечения иерархической структуры записей и полей в наборе данных. В слабоструктурированных данных, сущности, принадлежащие одному и тому же классу данных, могут иметь разные атрибуты. Вопросы, касающиеся слабоструктурированных данных, их классификации и возможных путей моделирования рассматривались в работах [1,2,3].
Элементы реализации идеи слабоструктурированной обработки и хранения данных имеются в бессхемных БД, относящихся к типу NoSQL [4] систем. Их особенностью, в частности является горизонтальное масштабирование хранилища данных и поддержка поиска и индексирования по произвольным полям, а в некоторых БД имеется возможность составления произвольных запросов выборки данных. Наиболее простым способом реализации слабоструктурированного хранения данных является динамическое хранилище ключей и значений, как реализовано в БД Redis и Riak. Другим подходом к обеспечению возможности динамического изменения структуры БД является столбцовая реализация хранения данных (противоположно строковой в реляционных базах данных), при которой есть возможность определения разного количества столбцов для различных строк. По такому принципу устроены БД HBase, Cassandra, HyperTable.
Особый интерес в отношении хранения и поиска представляют слабоструктурированные данные, представленные в виде цельных документов, относящихся к какой-либо категории или классу. Типичным примером слабоструктурированного документа, однако, четко попадающего во вполне определенный класс, является «счет-фактура». Он является наиболее проверяемым документом при аудите, но наибольшее количество судебных разбирательств связано именно с ним, потому, что Налоговый кодекс РФ в статье 169 «Счет-фактура» лишь общие требования по их заполнению. Таким образом, организации могут различным образом формировать нумерацию, адрес, подписи и другие реквизиты документа в процессе своей деятельности, реформирования организации и принципов учета. Счета-фактуры компаний с иностранным капиталом (инвойсы) могут содержать поля практически не используемые в отечественных документах, например, поле Value Added Tax (налог на потребление, являющийся некоторым аналогом отечественного налога на добавленную стоимость) Следовательно, самым гибким путем адаптации автоматизированных систем обработки таких документов является применение документо-ориентированных БД.
К таковым, в частности, относятся БД MongoDB, CouchDB. В БД MongoDB документ будет относиться и храниться в какой-либо коллекции, а форматом хранения служит структура на языке JSON. Схема БД MongoDB полностью изменяемая, использующая технологию Google MapReduce, допускающая построения широкого спектра индексов документов: уникальных, составных, геопространственных и вложенных. Для устойчивости и надежности хранения данных применяется атомарность операций, журналирование, технология асинхронной репликации с сегментацией по нескольким наборам реплик. Бессхемная БД CouchDB также использует массово-списочные функции map/reduce, интерфейс REST API для непосредственной обработки удаленных данных через HTTP протокол, а также формат описания данных JSON.
Наряду с привлекательными возможностями документо-ориентированного хранения данных есть и особенности, которые не особенно приветствуются разработчиками автоматизированных систем на основе БД. Среди таковых: отсутствие транзакций, невозможность автоматического приведения типов данных, затрудненная работа с массивами данных в отношении их сортировки и фильтрации, требование приведения данных к определенному формату и отсутствие других привычных функций БД.
Является достаточно очевидным факт, что для поиска документов в документо-ориентированных базах данных методы, которые используются в БД класса SQL, являются малопригодными. Отметим также, что в бессхемных БД не менее важен не только точный поиск и индексация, но и поиск релевантных искомому документов. В связи с этим, важна разработка формальных методов и вычислений меры информационного подобия, схожести документов в смысле их информационной направленности и принадлежности к некоторому классу. В общем смысле, существует значительное количество мер в различных областях науки, начиная от простой декартовой до многогранных сложных вероятностных мер. Очевидно также, что большинство из известных мер невозможно применить в рассматриваемой области исследований.
В рамках настоящей работы ограничимся одним из перспективных подходов [7] к составлению меры информационного подобия – интерференционно-волновом. Такая мера подобия используется для получения релевантных документов в базе слабоструктурированных данных. Она показывает уровень соответствия между наиболее релевантным документом и документами БД. Мера принимает во внимание соседство лексических единиц (терминов) и тегов. Каждый из документов, принадлежащий к документам рассматриваемой БД и слабоструктурированный документ, предназначенный для поиска, должны быть предварительно обработаны с помощью индексации [5]. Принимаются во внимание два типа информации: структурная и текстовая. Структурная информация извлекается путем перехода к одному из методов представления. В данном случае, это составление карты путей документа. Текстовая информация представляет собой термин из словаря базы данных, который находится по тому или иному пути. Для генерации существенных признаков, при поиске требуемого слабоструктурированного документа и документов в БД используются оба типа информации. Оба типа информации накладываются друг на друга. В качестве результата мы получаем волновую интерференцию, которую рассмотрим подробнее. Поиск документа в БД основан на генерации волновой интерференции, посредством сравнения слабоструктурированного документа с каждым документом БД. Данное сравнение позволяет вычислить уровень подобия.
Пусть D, Q два слабоструктурированных документа, U – набор лингвистических единиц, который включает в себя документ D, и T – общее количество слов в словаре. Пусть u – лингвистическая единица, прошедшая фильтр стоп-слов и нормализованная при помощи правил и словаря лемм. Определим функцию f релевантности:
y(u) = 3 – лингвистическая единица u принадлежащая документу Q не существует в документе базы данных D;
y(u) = 2 – лингвистическая единица u принадлежащая документу Q существует в документе базы данных D, но является изолированной, без соседних слов в общих и не общих путях;
y(u) = 1 – лингвистическая единица u, принадлежащая документу Q существует в с как минимум 1 соседним элементом в общих и не общих путях, документа D базы данных.
Посредством интерференции волн, можно определить 3 вектора следующим образом: V0 (а так же V1 и V2), представим вектор содержащий последовательности различных уровней релевантности документа, таких как V0[J] (и V1[J], V2[J], соответственно), где J весовой коэффициент последовательности 0 (1,2 соответственно). Например, векторы интерференции для волновой интерференции со значениями V0[0]=[0,0,1]; V1[2]=[0,0,2] означают, что на уровне 0 искомая лингвистическая единица существует в документе, а на уровне 1 является изолированной без соседних слов в общих путях поиска документов. По аналогии с физической массой вещества, будем измерять вклад в информационную похожесть (релевантность документа) в «условных граммах», а весовые коэффициенты J-граммами.
Основной результат: модифицированная интерференционно-волновая мера информационного подобия
Задача меры подобия зафиксировать величину информационного подобия между обрабатываемым документом Q с каждым документом D базы данных.
Информационную меру подобия, аналогично работе [8] определим тремя векторами интерференции V0, V1, V2 где каждый связан с коэффициентом, отражающим релевантность данных, найденных на каждом уровне:
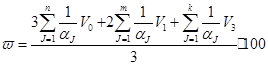 , (1)
, (1)
где:
![]() - максимальное число J-грамм в документе D и T число лингвистических единиц в документе;
- максимальное число J-грамм в документе D и T число лингвистических единиц в документе;
n, m, k – размеры векторов V0, V1, V2, соответственно.
Обобщим выражение (1) с целью нормирования меры.
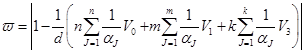 , (2)
, (2)
где ![]() .
.
Чтобы оценить производительность предложенного метода, в качестве критерия было выбрано время выполнения операций. Эксперименты проводились на тестовой базе данных содержавшей 150 слабоструктурированных документов. Общий объем данных в БД – 51 Мб, в базе данных содержатся УМК 25 различных дисциплин, которые характеризуются неоднородным размером. Задача системы определить, к какой из дисциплин относится документ из запроса. Тестирование времени индексации и определения информационного подобия по формуле (2), показало, что время индексации в зависимости о числа терминов в БД растет линейно, а не экспоненциально, что позволяет использовать предложенное выражение совместно и индексацией. Это делает возможным измерять информационное подобие документов в БД большого размера. Рост времени поиска, связан с увеличением размера документов базы данных, что приводит автоматически к увеличению числа слагаемых в слабоструктурированных документах в базе данных.
Заключение
В данной статье была представлена новая мера подобия, специализированная для слабоструктурированной информации. Мера состоит из понятия о волновой интерференции, извлечения векторов интерференции и затем, применения функции вычисления меры подобия. Метод основан на двух типах информации: структурной и текстовой. Структурная информация представляет собой путь из тегов ведущий к текстовой информации, представленной словарем и связанной с соседними элементами. Используя соседние элементы, имеется увеличение эффективности представления результатов поиска в БД. Система поиска в слабоструктурированной информации состоит из двух фаз: индексации и поиска. Система была проверена на тестовой базе данных и было выявлено, что время исполнения операция находится в линейной зависимости от количества терминов в БД.
Работа выполнена при финансовой поддержке РФФИ, проекты: 12-07-13120-офи_м_РЖД, 12-08-00798-а, 13-01-325-а, 13-01-00637-а, 13-08-12151-а.
Рецензенты:
Ляпин А.А., д.ф.-м.н., профессор, заведующий кафедрой информационных систем в строительстве Ростовского государственного строительного университета, г.Ростов-на-Дону.
Чернов А. В., д.т.н., профессор, заведующий кафедрой прикладной математики и вычислительной техники Ростовского государственного строительного университета, г.Ростов-на-Дону.
Библиографическая ссылка
Бутакова М.А., Климанская Е.В., Янц В.И. МЕРА ИНФОРМАЦИОННОГО ПОДОБИЯ ДЛЯ АНАЛИЗА СЛАБОСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ // Современные проблемы науки и образования. 2013. № 6. ;URL: https://science-education.ru/ru/article/view?id=11307 (дата обращения: 01.07.2026).