


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
CREATION OF SUBJECT DOMAIN’S THEMATIC STRUCTURES

Принципиально важным фактором, определяющим направление развития современных информационных систем, является неуклонное возрастание объемов информации. Даже отфильтрованные информационными системами результаты поиска представляют собой огромные потоки документальной информации. Это заставляет создателей автоматизированных информационно-поисковых систем (АИПС) все больше внимания уделять развитию инструментария представления результатов поиска в виде классификационных схем предметных областей или различных тематических структур. Приведем несколько примеров.
Интеллектуальная поисковая система Nigma [12] осуществляет автоматическую(на основе семантического анализа) кластеризацию результатов поиска, выдаваемых другими поисковыми системами Интернет (Google, Yahoo, MSN, Yandex, Rambler). Найденные документы разбиваются на кластеры, представленные в виде иерархического дерева. С помощью установки фильтров можно отсечь ненужные темы, что облегчает поиск необходимой информации. Просматривая описания кластеров, пользователь выбирает наиболее интересные для углубленного изучения.
Vivisimo (clusty) [8] – еще одна метапоисковая система, использующая другие поисковые системы для предварительного отбора текстовой информации cпоследующей кластеризацией результатов поиска. Алгоритмы работы vivisimo основаны на использовании стандартной модели работы с ключевыми словами и кластеризации результатов поиска. Группировка предварительно отобранных документов проводится по трем критериям:
- по частоте встречаемости ключевых слов в результатах поиска;
- по поисковым системам, в которых были найдены документы;
- по доменным зонам (например, com, ru и др.).
Результаты кластеризации по ключевым словам представляются в виде списка пунктов меню, по которым возможна пересортировка результатов выдачи. При отображении документы кластера упорядочиваются по статистике найденных в них ключевых слов.
Аналогичный принцип отображения результатов кластеризации реализован австралийским поисковым сервером Mooter [11], на котором применяется визуальный подход к предоставлению результатов поиска по обрабатываемым запросам путем группировки результатов первичного поиска по категориям.
Другой поисковый сервер iBoogie [9] также группирует результаты поиска, но отображает их в виде, близком к экрану Проводника Windows.
Система контент-мониторинга InfoStream [10] применяется для решения задач автоматизированного сбора информации с открытых web-сайтов, ее обработки, систематизации и обеспечения доступа к ней в поисковых режимах. Одним из преимуществ системы по сравнению с традиционными сетевыми информационно-поисковыми системами является наличие аналитического инструментария, который позволяет пользователю в режиме реального времени не только получать результаты поиска, но и формировать дайджесты, строить сюжетные цепочки, анализировать взаимосвязь рубрик, динамику понятий и т.д.
Независимо от формы представления результатов, поисковые системы Интернета выдают список ссылок на найденные страницы. Пользователь при этом вынужден заниматься навигацией по найденным ссылкам, анализом страниц и поиском необходимой информации. Семантические поисковые системы AskNet [7] обеспечивают вывод ответов на запросы пользователей непосредственно на страницу результатов поиска.
В справочно-информационной системе ВИНИТИ [13] вывод результатов поиска осуществляется поэтапно. После проведения поиска формируется сообщение, содержащее текст запроса, дату поиска, имя БД, в которой проводился поиск, сведения о количестве найденных документов и гиперссылку для перехода на просмотр краткой формы описания документов. Это сообщение записывается в историю поиска, которая отражается на экране. После анализа результатов поиска в краткой форме и выбора условий вывода на экран выводится выбранная форма документов.
В [1] описывается методика автоматической рубрикации, которая используется для распределения результатов поиска по определенным темам в поисково-аналитической системе «Галактика-Зум». Предварительно системой определяются информационные портреты (ключевые темы конкретных рубрик) по оригинальной технологии выделения и ранжирования ключевых тем. Затем автоматически происходит классификация документов методом сравнения информационных портретов документа и заданных рубрик.
Таким образом, тенденции развития поисковых систем заключаются в постепенном расширении традиционных функций и активном подключении к поисковым механизмам интеллектуальных аналитических возможностей. Один из способов интеллектуализации АИПС состоит в представлении результатов поиска в виде тематических структур (ТС) предметных областей, в качестве которых рассматриваются области научных исследований.
Задача построения (ТС) предметных областей основывается на:
- формализованном представлении тематической структуры как упорядоченной совокупности понятий предметной области и отношений между ними;
- оценке совместной встречаемости терминов индексирования в документальных БД;
- анализе и обобщении семантических элементов.
В основе построения тематической структуры лежат следующие принципы:
1. Модель тематической структуры области исследований представляется в виде кортежа множеств:
Ω = <P, V, R>,
где Р – множество понятий предметной области; V – множество свойств понятий; R – множество отношений из PxV.
Используются идеи аксиоматической теории сходства, устанавливаются критерии сходства понятий в локальном и глобальном смысле [5].
2. Формализация представления тематического сходства понятий в рамках направления области исследований основана на использовании глобального сходства, определяемого общностью свойств на подмножестве понятий.
3. Для структуризации понятий тематических направлений используются семантические отношения иерархического (род – вид, целое – часть, проблема – аспект) и неиерархического типа (объект – метод, объект – область применения и т. д.).
Предполагается, что тематическая структура имплицитно содержится в выборке документов, полученной в результате поисков по запросам пользователя, являющейся моделью предметной области исследований:
B=<T, D, R'>- модель предметной области,
где Т – множество терминов индексирования; D – множество документов; R' – множество отношений изTxD.
В этом случае задача экспликации состоит в поиске способа отображения модели тематической выборки документов в модель тематической структуры области исследований Ω, т. е. w: B ® Ω. Исходя из этого, можно наметить два этапа решения этой задачи:
- на первом этапе из заданного множества понятий P необходимо выделить группы тематически связанных понятий. В формальной постановке это соответствует задаче классификации объектов-понятий и требует задания сходства между понятиями, а также выбора метода группирования;
- на втором этапе решения задачи проводится упорядочение понятий внутри выделенных групп и придание им определенной структуры в соответствии с заданным типом отношений.
В основе формальных методов классификации лежит отношение сходства между классифицируемыми объектами, при этом пользуются попарным сравнением объектов, т.е. отношение сходства рассматривается как бинарное. Аксиоматическая теория сходства рассматривает понятие сходства как отношение толерантности – рефлексивное и симметричное бинарное отношение. Для структуризации тематической области используется формализованное представление локального сходства между терминами индексирования в документах выборки.
Рассмотрим множество T={ t1, t2..., ti,..., tN} терминов индексирования множества документов D = {d1, d2,..., dj,..., dM }. На множестве Т будем считать заданным набор признаков (свойств), т.е. одноместных предикатов вида P(ti), принимающих значения 0 или 1. Если P(ti) = 1, то будем говорить, что ti обладает признаком Рi. В качестве множества всех рассматриваемых признаков в данном случае принимается множество документов D. Тогда соответствие f: T®D устанавливает для каждого ti все признаки, которыми обладает термин ti (все документы, заиндексированные термином ti). Это множество признаков будем обозначать D(ti), D(ti) ÍD. Обратное соответствие -f-1: D®T- сопоставляет каждому признаку dj множество T(dj) тех терминов, для которых выполнен этот признак. Соответствие устанавливает отношение на множествах терминов Т и документов D и определяется как подмножество R декартова произведения множеств TхD, RÍTxD.
Рассмотрим тройку <T, D, R>, где Т – множество объектов (терминов), D – множество признаков (документов), R – отношение из TxD. Будем называть упорядоченную тройку С=С<Т, D, R> картой [13]. Таким образом, карта – это экспликация понятия «множество с признаками». Вхождение множества Т в карту (т. е, задание на Т признаков) позволяет определить на множестве Т отношение локального сходства. Отношение ![]() на множестве Т является отношением толерантности (сходства) при соблюдении следующих условий:
на множестве Т является отношением толерантности (сходства) при соблюдении следующих условий:
- tiτ ti.ti
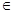 T – рефлективность;
T – рефлективность; - ti τ tj.
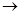 tj τ ti , tjT, tiT, – симметричность;
tj τ ti , tjT, tiT, – симметричность; - tiτtj.&tiτtk.
 не →ti τ tk – интранзитивность.
не →ti τ tk – интранзитивность.
Объекты (термины) локально сходны, тогда и только тогда, когда:
D(ti) ∩ D(tj) = Ø,
т.е. локальное сходство требует наличия общего признака у пары терминов (документов) и является бинарным однородным отношением.
Множество Т с заданным на нем отношением сходства τ является пространством толерантности Т![]() = < Т, τ>. Его можно изобразить неориентированным графом G(T, τ) – терминологической сетью, в которой ребрами соединены только те вершины, которые связаны отношением τ. Преобразование локального сходства пары терминов в глобальное сходство подмножества терминов может быть достигнуто двумя путями: либо построением классов толерантности на множестве Т, либо установлением отношения транзитивного замыкания τ на множестве Т [1].
= < Т, τ>. Его можно изобразить неориентированным графом G(T, τ) – терминологической сетью, в которой ребрами соединены только те вершины, которые связаны отношением τ. Преобразование локального сходства пары терминов в глобальное сходство подмножества терминов может быть достигнуто двумя путями: либо построением классов толерантности на множестве Т, либо установлением отношения транзитивного замыкания τ на множестве Т [1].
Таким образом, задача выделения на графе классов толерантности или поиска транзитивного замыкания отношения τ, рассматриваемая нами как задача разбиения терминологической сети, моделирующей тематическую область исследований на отдельные составляющие (направления) – подмножества связанных тематическим сходством терминов, сводится к разбиению графа G(T, τ) на максимально полные подграфы или связные его компоненты [4].
Следующим этапом решения задачи построения тематической структуры является структуризация терминов внутри выделенного направления. Для этого определяются основные виды (классы) семантических отношений и находятся статистические характеристики их появления в предметной области. Затем с помощью статистических критериев решается вопрос о принадлежности каждой пары терминов одному из заданных классов отношении.
Для этого используются методы кластерного анализа и распознавания образов [2, 3], причем терминологическая сеть G(T, τ) рассматривается как объект кластеризации, а тип отношений между терминами индексирования является объектом распознавания.
В результате анализа методов кластеризации и особенностей их использования для структуризации тематических областей выбрана односвязывающая кластер–процедура [2]. При этом методе достаточно одного звена, чтобы вся цепь оказалась собранной, что позволяет учитывать сходство терминов при формировании тематического направления не только по их совместной встречаемости, но и по сходству их окружения. Полученные связные компоненты не пересекаются, т.е. каждый термин присутствует только в одной группе, что приводит к четким границам отдельных направлений, выделяемых в тематической области.
Ситуация, возникающая при анализе пар терминов, связанных определенными семантическими отношениями и состоящая в обнаружении и выделении признаков, характеризующих эти пары, а затем в отнесении каждой пары к одному из заданных классов отношений, аналогична ситуации, возникающей в системах распознавания образов. Анализ семантических отношений между терминами индексирования в базе данных предполагает установление типа отношений для каждой пары терминов, упорядочение и структуризацию терминов на основе определенного типа отношений. Решение этой задачи становится возможным на основе выявления устойчивых отношений между терминами и статистических закономерностей их появления с увеличением объема БД.
Сформированная на основе множества документов, полученного в результате поискового процесса, тематическая структура представляет собой новый информационный объект, который позволяет:
- структурировать полученное в результате поиска множество документов;
- осуществлять навигацию по этому множеству;
- анализировать информацию, содержащуюся в полученных документах, относящихся к структурным компонентам предметной области в соответствии с их значимостью;
- решить проблему дальнейшего повышения уровня обобщения информации.
Рецензенты:
Романов В.П., д.т.н., профессор, профессор кафедры информатики РЭУ им. Г.В. Плеханова Минобрнауки РФ, г. Москва.
Колмаков И.Б., д.э.н., к.ф.-м.н., профессор, профессор кафедры информатики РЭУ им. Г.В. Плеханова Минобрнауки РФ, г. Москва.
[1] Под транзитивным замыканием (или просто замыканием) отношения τ понимается бесконечное объединение τi. Обозначим замыкание как τ *, тогда τ *= τ1Èτ 2 È ... Èτ k
Библиографическая ссылка
Васина Е.Н., Козлова И.В. ПОСТРОЕНИЕ ТЕМАТИЧЕСКИХ СТРУКТУР ПРЕДМЕТНЫХ ОБЛАСТЕЙ // Современные проблемы науки и образования. 2013. № 6. ;URL: https://science-education.ru/en/article/view?id=11782 (дата обращения: 01.07.2026).