


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
DEVELOPMENT OF THE INTERNET CATALOGUE FOR THE ORGANIZATION OF ACCESS TO CORPORATE DATA WAREHOUSE OF ELECTRONIC DOCUMENTS OF TPU

Введение. Безусловно, что создание и поддержка в актуальном состоянии корпоративного хранилища электронных документов является важной задачей [3]. Тем не менее после создания соответствующих структур для хранения электронных документов появляется задача об удобном доступе к ним и обнаруживаемости их поисковыми системами.
В Томском политехническом университете (ТПУ) в качестве пилотного проекта разрабатывается система электронного хранилища документов на основе программного продукта Oracle Universal Content Management (Oracle UCM) [1]. Сам продукт Oracle UCM в своей работе использует СУБД Oracle для хранения электронных документов и их полнотекстовой индексации, а также набор стандартных пользовательских веб-интерфейсов и веб-сервисов для взаимодействия с хранилищем электронных документов, как представлено на рис. 1.
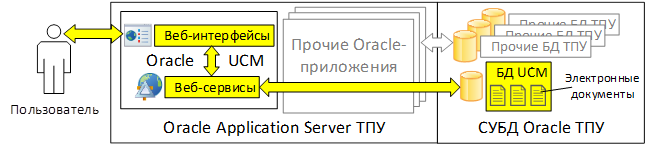
Рис. 1. Обобщённая архитектура Oracle UCM в инфраструктуре ТПУ
В традиционном варианте доступ пользователей к электронным документам Oracle UCM производится по траектории, выделенной на схеме желтым цветом. При этом задействованы стандартные пользовательские веб-интерфейсы и сервисы Oracle UCM.
Цель исследования
Варианты решения. С одной стороны, для построения интернет-каталога поверх хранилища электронных документов в корпоративной сети ТПУ возможно было бы воспользоваться существующими возможностями Oracle UCM, как показано на рис. 1. При этом дизайн пользовательского интерфейса интернет-каталога и его функционал ограничивались бы возможностями компонент UCM.
Данный вариант был рассмотрен и отвергнут, как непригодный с точки зрения дальнейшего расширения функционала. Готовые пользовательские интерфейсы Oracle UCM являются стандартными по дизайну и функциям, что не всегда удобно для встраивания в существующие корпоративные системы.
С другой стороны, для построения интернет-каталога электронных документов возможно разработать свой пользовательский веб-интерфейс, взаимодействующий напрямую с базовыми веб-сервисами Oracle UCM. Пример интернет-каталога электронных документов, построенного по второму варианту архитектуры, показан на рис. 2.
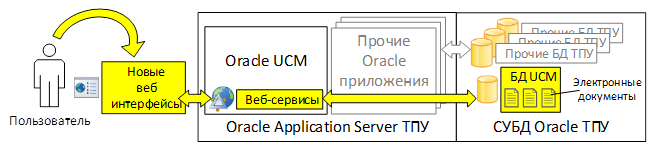
Рис. 2. Вариант построения интернет-каталога с использованием нового пользовательского веб-интерфейса
Такой вариант позволит легче изменять и расширять функционал интернет-каталога в дальнейшем, по новому осуществляя обработку информации, извлечённой из хранилища электронных документов. Отличительной особенностью этого варианта построения интернет-каталога является возможность беспрепятственной модернизации его бизнес-логики и дизайна. Такой вариант авторам работы видится более предпочтительным, так как предоставляет большую свободу действий в дальнейшем наращивании возможностей интернет-каталога.
Проектирование. В процессе проектирования выбранного варианта были определены детали внутренней архитектуры интернет-каталога и принципы взаимосвязи с корпоративным хранилищем электронных документов. Для взаимодействия с хранилищем документов возможны несколько протоколов взаимодействия: Remote IDC (RIDC) [5], Simple Object Access Protocol (SOAP) [8]. Протокол RIDC является проприетарной разработкой Oracle и, разумеется, обладает большими возможностями по взаимодействию с Oracle UCM. Но Oracle предоставляет программные библиотеки с высокоуровневыми функциями RDIC только для языка Java. Второй доступный для взаимодействия протокол (SOAP) – является отлично документированным международным стандартом [8] и обладает открытыми готовыми библиотеками на многих языках программирования высокого уровня (PHP, C#, Java, Pyton и т.д.). Вследствие этого в работе был использован именно протокол SOAP. Использование SOAP определило сервис-ориентированный (SOA, Service-Oriented Architecture [7]) тип архитектуры интернет-каталога. Архитектура SOA характерна слабым связыванием компонент, повторным использованием сервисов и высокой расширяемостью. Схема общего взаимодействия проектируемого веб-приложения интернет-каталога, сервера Oracle UCM и глобальных поисковых систем представлена на рис. 3.
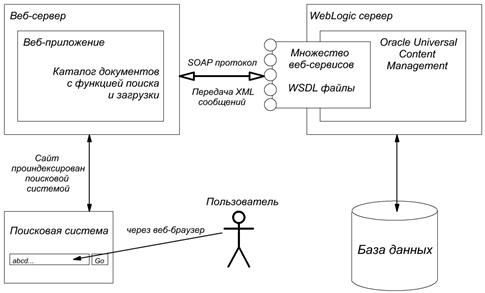
Рис. 3. Структура взаимоотношений компонент системы
На основе проведенного анализа веб-сервисов Oracle UCM установлено, что для работы интернет-каталога достаточным будет использование трех базовых веб-сервисов Oracle UCM: DOC_INFO, GET_FILE, GET_SEARCH_RESULTS, позволяющих получать информацию о документе, загружать документ на компьютер клиента и производить поиск документа по требуемым атрибутам, соответственно.
В процессе проектирования интернет-каталога использован унифицированный язык моделирования UML (спецификация UML 2.4.1, принятая ISO/IEC 19501:2005), с помощью которого построены диаграмма прецедентов (вариантов использования) и диаграмма классов [9].
Реализация. Веб-приложение интернет-каталога реализовано при помощи ASP.NET MVC фреймворка на языке C# с использованием Visual Studio 2012.
На рис. 4 представлен фрагмент страницы с документами, найденными при выполнении полнотекстового поискового запроса с ключевым словом «шаблон». Значимым является то, что искомое ключевое слово было найдено именно в содержимом документов, а не в их метаописании (заголовке, списке авторов, кратком описании и т.п.).
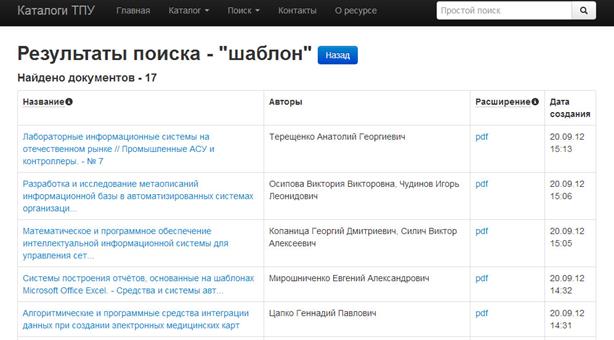
Рис. 4. Фрагмент результатов полнотекстового поискового запроса по ключевому слову «шаблон»
При реализации интернет-каталога использовалась концепция MVC (Model-View-Controller), согласно которой приложение было разделено на три области: модель данных, представления и контроллеры. В рамках среды разработки Visual Studio 2012 решение состоит из двух частей-проектов. Один из проектов представляет собой библиотеку классов C# и отвечает за предоставление доступа к модели данных. Второй проект отвечает за пользовательский интерфейс клиентской части и содержит представления для визуализации информации, пользовательского интерфейса, а также контроллеры для связи между моделью и представлением. В целом в процессе кодирования интернет-каталога были реализованы: модель данных, 12 представлений (с использованием рабочего набора библиотеки Razor [6] и дополнительного пакета twitter.bootstrap), 3 контроллера.
Пробная эксплуатация. Разработанный интернет-каталог был развернут для тестирования и пробной эксплуатации на выделенном сервере Томского политехнического университета [2] под управлением операционной системы Windows 7 и веб-сервера Internet Information Server v.7.0. Для проверки обнаруживаемости контента интернет-каталога из внешних поисковых систем ресурс был поставлен в очередь на индексирование в поисковых системах Google и Яндекс с помощью соответствующего программного инструментария [4].
В течение одной недели поисковая система Google внесла в свою индексную базу данных более 500 HTML-страниц из установленного интернет-каталога. Каждая из проиндексированных страниц являлась запросом на поиск документов по автору или названию. В связи с этим информация о документах интернет-каталога обнаруживается посредством сервиса Google. На рис. 5 приведены результаты поискового запроса по ключевой фразе «ГИС модуль для информационной системы агрохимического», где видно, что ресурс catalog1.vt.tpu.ru выдается поисковым механизмом Google на первом месте среди примерно 5540 результатов.
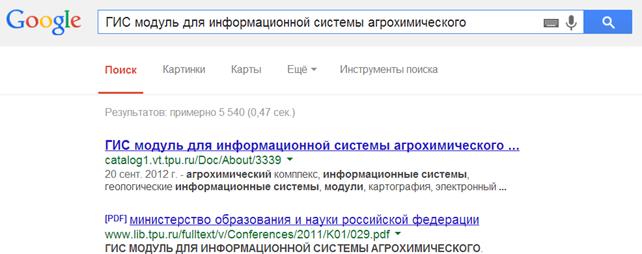
Рис. 5. Результаты поисковой системы Google на запрос «ГИС модуль для информационной системы агрохимического»
Разработанный программный код интернет-каталога электронных документов не является полностью законченным. Перспективой модернизации ресурса является повышение его быстродействия и отказоустойчивости, перехват инъекций программного кода в поисковых запросах, дальнейшее продвижение интернет-ресурса в рейтингах поисковых систем.
Рецензенты:
Ким В.Л., д.т.н., профессор кафедры вычислительной техники Института кибернетики ФГБОУ ВПО «НИ ТПУ», г. Томск.
Авдеева Д.К., д.т.н., профессор, директор ООО «Медприбор», г. Томск.
Библиографическая ссылка
Шерстнёв В.С., Распопов А.В. РАЗРАБОТКА ИНТЕРНЕТ-КАТАЛОГА ДЛЯ ОРГАНИЗАЦИИ ДОСТУПА К КОРПОРАТИВНОМУ ХРАНИЛИЩУ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ ТПУ // Современные проблемы науки и образования. 2013. № 6. ;URL: https://science-education.ru/en/article/view?id=11130 (дата обращения: 01.07.2026).