


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
PIPELINE-PARALLEL PROCESSING OF INTEGRATED DATA STREAMS

Введение
Одной из важнейших характеристик обработки информации является эффективность параллельных вычислений. К настоящему моменту известны работы по написанию распараллеливающих компиляторов. Несмотря на это, автоматическое распараллеливание последовательных программ остается сложной нерешенной задачей. Требуется создание новых эффективных инструментов для обработки потоков разнородных данных на современных высокопроизводительных вычислительных системах. Анализ ситуации позволил сделать следующие выводы:
1. Эффективному автоматическому распараллеливанию поддается небольшое множество последовательных программ, что обуславливает целесообразность применения упрощенных методов автоматизации распараллеливания.
2. Одним из эффективных решений является создание универсальных математических библиотек, ориентированных на решение широкого спектра задач, адаптированных к архитектуре кластерных вычислителей, снабженных графическими процессорами с архитектурой Nvidia и AMD.
Среди различных методов повышения эффективности обработки информации выделяются интеллектуальные методы, которые опираются на нейронные сети, генетические алгоритмы, продукционные правила, методы распознавания образов, когнитивную графику и другие инструменты искусственного интеллекта [2, 3].
Интеллектуальная обработка информации
В качестве примера можно привести перспективный комплекс интеллектуальной обработки интегрированной информации (телеметрия, целевая и командная информация) на наземной станции космического назначения (НС КИС), связывающей центр управления полетом (ЦУП) и космический аппарат (КА). Структурная схема взаимодействия указанных компонентов показана на рис. 1.
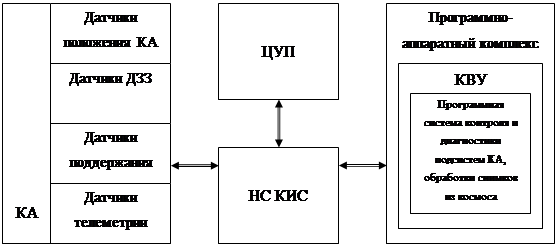
Рис. 1. Структурная схема взаимодействия компонентов
Очевидна актуальность интеграции современных кластерных вычислительных устройств (КВУ) с интеллектуальными системами для унифицированной обработки целевой, телеметрической и командной информации. Перспективные наземные станции, снабженные КВУ и программным обеспечением, позволяют вести полный комплекс обработки интегрированной информации, обеспечивают расширение функциональных возможностей и повышение автономности НС КИС, позволяют рационально распределять задачи между НС КИС и ЦУП.
В настоящее время реализован прототип высокопроизводительной программной нейросетевой системы, оптимизированной под задачи обработки данных, распознавания образов, контроля и диагностики космических подсистем. Сформированы принципы функционирования программной системы в составе НС КИС космического назначения. Актуальная задача формируется из библиотечных модулей и решается на КВУ, что обеспечивает требуемое быстродействие. Система, построенная на основе интеграции различных методов обработки информации, способна решать и другие задачи широкого назначения.
Предложена общая концепция построения и архитектура программного комплекса для решения задач конвейерно-параллельной обработки информации в гетерогенной среде. При этом учитываются возможности параллелизма данных, множества объектов и смежных операций. Особое значение придается конвейерной обработке как особому виду параллелизма. Разработанный комплекс инструментальных программных средств включает программные средства преобразования поступающих данных в специально предназначенную для последующего анализа конвейерно-параллельную форму; блок анализа данных на основе нейросетевых методов [4], предназначенный для обработки поступающих данных; универсальный графический интерфейс проектирования прикладных систем с помощью визуально-блочного программирования. Предложенная архитектура и программно-аппаратные инструменты позволяют полноценно использовать ресурсы гетерогенной среды GPU-кластера [1, 5].
Экспериментальные исследования показывают, что GPU-кластер является достаточно эффективным решением и позволяет легко наращивать производительность системы. Среди рассмотренных в работе вариантов реализации высокопроизводительных алгоритмов на основе GPU-кластеров выбрана модель параллелизма данных, позволяющая строить эффективный конвейер обработки, поддерживаемый программным комплексом.
Предложены программные библиотеки, позволяющие в комплексе решать задачи автоматизации распараллеливания задач мониторинга и обработки информации на высокопроизводительных вычислительных системах. Разработаны принципы построения кроссплатформенной системы распараллеливания программ на графических процессорах для платформы NET. Разработаны библиотеки, реализующие задачи линейной алгебры, обработки изображений в частотной области, включая спектрографический метод «закраски» с применением GPU. Библиотеки существенно облегчают решение задачи конвейерно-параллельной обработки информации в гетерогенной среде. Созданные библиотеки были практически использованы для решения задач мониторинга, обработки потоков сигналов и снимков. Библиотеки характеризуются тем, что содержат необходимый набор готовых инструментов для прикладных программистов и обеспечивают требуемую функциональность.
Экспериментальные исследования разработанных библиотек показали, что использование GPU, поддерживающих технологию OpenCL, существенно сокращает время обработки потоков данных, но при этом точность вычислений может понизиться по сравнению с вычислениями на CPU. Большое влияние на скорость обработки оказывают накладные расходы по передаче данных, производительность на GPU падает в программах, где много обращений к памяти.
По сравнению с традиционной организацией вычислений общего назначения использование возможностей архитектуры CUDA обеспечивает следующие преимущества:
- более эффективные транзакции между памятью центрального процессора и видеопамятью;
- полная аппаратная поддержка целочисленных и побитовых операций;
- поддержка компиляции GPU-кода.
Разработанные программные компоненты библиотек обеспечивают: масштабируемость вычислений при увеличении числа вычислительных ядер и вычислительных узлов; возможность конвейерно-параллельной обработки потоков данных и решения задач контроля и диагностики.
Заключение
В ходе выполненного исследования разработано базовое математическое и программное обеспечение для автоматизации конвейерно-параллельных вычислений в гетерогенной среде при обработке интегрированной информации. К основным результатам можно отнести
1) разработку средств поддержки конвейерно-параллельной работы гетерогенных суперкомпьютерных систем, построенных на основе универсальных и графических процессоров;
2) универсальные библиотеки для решения комплекса задач мониторинга и обработки потоков данных на GPU.
Разработанные приложения являются кроссплатформенными как относительно аппаратуры (Nvidia и AMD), так и операционных систем (Windows, Linux). Достигнуто быстродействие приложений, сравнимое с эталонными реализациями стандарта OpenCL на целевых платформах. Предлагаемые библиотеки значительно упрощают программирование современных вычислительных систем, оснащенных графическими процессорами, при решении задач с различными видами параллелизма.
Работа поддержана Министерством образования и науки Российской Федерации (Государственный контракт № 14.514.11.4109 по теме «Разработка алгоритмов и методов организации высокопроизводительных конвейерно-параллельных вычислений в облачных средах»).
Рецензенты:
Славин О.А., д.т.н., заведующий лабораторией, ФГБУН Институт системного анализа Российской академии наук (ИСА РАН), г. Москва.
Знаменский С.В., д.ф.-м.н., заведующий лабораторией, ФГБУН Институт программных систем им. А.К. Айламазяна Российской академии наук, Исследовательский центр системного анализа, с. Веськово.
Библиографическая ссылка
Тищенко И.П., Хачумов В.М. КОНВЕЙЕРНО-ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ИНТЕГРИРОВАННЫХ ПОТОКОВ ДАННЫХ // Современные проблемы науки и образования. 2013. № 5. ;URL: https://science-education.ru/en/article/view?id=10667 (дата обращения: 07.07.2026).