



В настоящее время сложилось множество подходов к сегментированию рынков, среди которых трудно ориентироваться практическим работникам. Поэтому в работе была предпринята попытка составить научный путеводитель в пространстве современных методов и инструментов сегментирования потребительских рынков.
Сегмент рынка (market segment) – совокупность потребителей, характеризующихся однотипной реакцией на предлагаемые продукты и другие элементы комплекса маркетинга.
Сегментирование рынка представляет собой формальную процедуру, основанную на применении методов многомерного статистического анализа к результатам маркетинговых исследований.
При сегментировании потребительского рынка сначала используют объективные переменные сегментирования (социально-экономические, демографические, географические), а затем субъективные переменные сегментирования (психографические, поведенческие, личностные). Из полного перечня признаков сегментирования обычно выбирают один или несколько наиболее важных. Большое число переменных сегментирования может привести к чрезмерному дроблению сегмента.
Выделяют два подхода к сегментированию рынков: «a priory» и «post hoc».
В рамках первого подхода считается, что предварительно известны признаки сегментирования, емкость сегментов, их количество, характеристики, карта интересов. То есть предполагается, что сегментные группы потребителей продуктов в данном методе уже сформированы («a priori»).
В рамках второго подхода («post hoc»), предполагается неопределенность признаков сегментирования и сущности самих сегментов. Необходимо произвести поиск признаков сегментирования с последующим выбором и описанием сегментов.
Многообразие задач сегментирования и условий формирования рынков породили множество методов сегментирования. В настоящее время в практике исследования рынков получили широкое распространение следующие методы сегментирования:
– метод многомерной классификации;
– метод корреляционного сегментирования – «К-сегментирование»;
– методы архетиповой сегментации;
– метод сегментации по выгодам;
– метод построения сетки сегментации;
– метод группировок;
– метод функциональных карт;
– метод сегментации на основе матриц Абеля;
– метод сегментации потребителей по степени их лояльности;
– метод сегментации по выгодам.
Среди методов сегментирования, которые появились достаточно недавно, можно назвать следующие методы:
– метод коллаборативной фильтрации;
– метод латентных моделей;
– метод гибкого (flexible) сегментирования;
– метод компонентного (componential) сегментирования.
Среди методов сегментирования наиболее мощным инструментом являются методы многомерной классификации данных. Применение метода многомерной классификации называют кластерным анализом.
Кластерный
анализ это совокупность методов, позволяющих классифицировать многомерные
наблюдения, каждое из которых описывается набором исходных переменных ![]() . Целью кластерного анализа является
образование групп сходных между собой объектов, которые принято называть
кластерами.
. Целью кластерного анализа является
образование групп сходных между собой объектов, которые принято называть
кластерами.
Задачу классификации нужно отличать от задачи группировки. Задача группировки состоит в том, что данные разбиваются сначала по уровням одного признака, затем по уровням другого признака и т.д. В отличие от задачи группировки в кластерном анализе формирование групп объектов (классов) производится с учетом всех группировочных признаков одновременно.
Для решения задачи классификации необходимо ввести понятие сходства объектов по наблюдаемым признакам. В каждый класс должны попасть объекты, обладающие определенной степенью сходства.
Для количественной оценки сходства вводится понятие метрики. Сходство между объектами будет определяться в зависимости от расстояния в выбранном метрическом пространстве. Если объект, описываемый m признаками представить точкой в m-мерном пространстве, то сходство объектов друг с другом будет определяться как расстояние в данном метрическом пространстве.
В кластерном анализе используется большое разнообразие способов измерения расстояний (метрик). Примером одной из наиболее распространенные метрик сходства является евклидово расстояние:
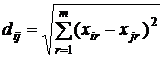 (1)
(1)
где ![]() – расстояние между i –м и j – м объектами;
– расстояние между i –м и j – м объектами;
![]() – значение r-го признака соответственно у i-го и j-го
объекта;
– значение r-го признака соответственно у i-го и j-го
объекта;
![]() , где n – объем выборки;
, где n – объем выборки;
![]() , где m – количество признаков.
, где m – количество признаков.
Для решения задачи классификации необходимо рассматривать расстояния между каждой парой объектов. Расстояния между парами объектов сводятся в матрицу сходства. Это симметричная матрица. По диагонали матрицы располагаются нулевые значения.
Оценивать
сходство объектов с помощью мер расстояния удобно при использовании числовых
признаков. Но часто встречаются признаки, измеренные в других шкалах (например,
в ранговой, или, вообще, в номинальной). В этом случае все признаки,
используемые для классификации, приводятся к представлению в бинарном
(двоичном) коде. Предположим, что такое преобразование было выполнено. То есть
каждый объект описывается вектором ![]()
![]() , каждая из компонент которого
принимает значения 0 или 1.
, каждая из компонент которого
принимает значения 0 или 1.
Для измерения сходства I-го и j-го объектов введем следующие обозначения частот:
![]() – число совпадающих единичных
признаков у обоих пар объектов (пар (1,1));
– число совпадающих единичных
признаков у обоих пар объектов (пар (1,1));
![]() – число совпадающих нулевых
признаков у обоих пар объектов (пар (0,0));
– число совпадающих нулевых
признаков у обоих пар объектов (пар (0,0));
![]() – число совпадающих единичных
признаков у i-го и нулевых признаков у
j-го объектов (пар (1,0));
– число совпадающих единичных
признаков у i-го и нулевых признаков у
j-го объектов (пар (1,0));
![]() – число совпадающих нулевых
признаков у i-го и единичных признаков
у j-го объектов (пар (0,1));
– число совпадающих нулевых
признаков у i-го и единичных признаков
у j-го объектов (пар (0,1));
![]() ,
,![]() – число единичных признаков у i-го и единичных признаков у j-го объектов соответственно;
– число единичных признаков у i-го и единичных признаков у j-го объектов соответственно;
![]() ,
,![]() – число нулевых признаков у i-го и нулевых признаков у j-го объектов соответственно;
– число нулевых признаков у i-го и нулевых признаков у j-го объектов соответственно;
![]() – общее число совпадающих признаков;
– общее число совпадающих признаков;
![]() – общее число несовпадающих
признаков;
– общее число несовпадающих
признаков;
![]() – общее число признаков, по которым
осуществляется сравнение.
– общее число признаков, по которым
осуществляется сравнение.
В качестве примеров мер подобия в бинарной шкале измерения можно привести коэффициент Рао (2) и коэффициент Хаммана (3):
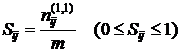 (2)
(2)
![]() (3)
(3)
Другой
важной величиной в кластерном анализе является расстояние между целыми группами
объектов. Приведем примеры наиболее распространенных расстояний и мер близости,
характеризующих взаимное расположение отдельных групп объектов. Пусть ![]() – t-я группа (класс, кластер)
объектов,
– t-я группа (класс, кластер)
объектов, ![]() – число объектов, образующих
группу
– число объектов, образующих
группу ![]() , вектор
, вектор ![]() – среднее арифметическое объектов,
входящих в группу
– среднее арифметическое объектов,
входящих в группу![]() (другими словами
(другими словами ![]() – «центр тяжести» t-й группы), a
– «центр тяжести» t-й группы), a ![]() – расстояние между группами
– расстояние между группами ![]() и
и ![]() .
.
Наиболее
распространенными методами определения расстояния между кластерами ![]() и
и ![]() являются:
метод «ближайшего соседа» (4), метод «дальнего соседа» (5), метод оценки
расстояния между центрами тяжести (6).
являются:
метод «ближайшего соседа» (4), метод «дальнего соседа» (5), метод оценки
расстояния между центрами тяжести (6).
![]() (4)
(4)
![]() (5)
(5)
![]() (6)
(6)
Среди
всех методов классификации самым распространенными являются иерархические
агломеративные методы. Основная идея этих методов состоит в том, что на первом
шаге каждый объект выборки рассматривается как отдельный кластер. Иерархическая
процедура состоит в пошаговом объединении наиболее близких классов. Близость
классов оценивается по матрице расстояний или матрице сходства. На первом шаге
матрица сходства имеет размерность ![]() . На
следующем шаге при объединении двух классов матрица сходства пересчитывается.
Размерность матрицы сокращается на единицу и становится [
. На
следующем шаге при объединении двух классов матрица сходства пересчитывается.
Размерность матрицы сокращается на единицу и становится [![]() ]. Процесс завершается за
]. Процесс завершается за ![]() шагов, когда все объекты будут
объединены в один класс.
шагов, когда все объекты будут
объединены в один класс.
Процесс объединения объектов можно изобразить в виде графа-дерева (дендрограммы). На дендрограмме указываются номера объединяемых объектов и расстояния, при которых произошли объединения. При выделении классов руководствуются скачками метрики сходства на дендрограмме.
Большое распространение в практике экономического анализа получил метод многомерной классификации, который известен под названием «метод k-средних». Он был предложен Мак-Куином. Этот метод классификации относится к группе итеративных методов классификации. Существует множество модификаций этого метода. Рассмотрим алгоритм классификации в его первоначальном виде.
Пусть
имеется n объектов (наблюдений),
каждый из которых характеризуется m
признаками ![]() . Необходимо разбить наблюдения
на заданное число классов – k.
. Необходимо разбить наблюдения
на заданное число классов – k.
Шаг ноль. Из n точек исследуемой совокупности случайным образом отбирается k точек. Эти точки принимаются как центры классов.
Итерация. Множество точек разбивается на k классов по минимуму расстояния до центров классов. Для расчета расстояния можно использовать любую метрику. Чаще всего используется евклидово расстояние. Производится пересчет центров классов, как центров тяжести точек, присоединенных к классам.
Проверка. Если центры классов при выполнении очередной итерации не изменились, то процесс классификации завершается, иначе переходим к пункту «итерация».
Существует большая группа алгоритмов многомерной классификации, основанная на применении теории графов. Представителем этой группы является алгоритм «Краб» [2]. На сходных принципах организована группа алгоритмов FOREL.
Рассмотрим принципы работы алгоритма «Краб». Работа алгоритма начинается с нахождения пары точек с минимальным расстоянием между ними. Эти точки соединяются ребром графа. Затем соединяются следующие самые близкие точки, из числа не присоединенных, к уже построенной части графа. Эта процедура повторяется до тех пор, пока все точки не окажутся соединенными ребрами графа.
Такой граф не будет иметь петель, и суммарная длина всех его
ребер будет минимальной. Граф, обладающий такими свойствами, называется
кратчайшим незамкнутым путем (КНП). Для разбиения множества точек графа на два
таксона разрывают самое длинное ребро. Далее процесс повторяется до получения
адекватной структуры классов. Алгоритм «Краб» имеет множество модификаций. При
дальнейшем развитии алгоритма вводится понятие ![]() – расстояния и критерии качества разбиения.
– расстояния и критерии качества разбиения.
При исследовании социально-экономических систем подавляющее большинство явлений не поддается прямому измерению (умственные способности, личностные качества, толерантность, компетентность, мобильность, политические убеждения и т.д.), что привело к появлению нового понятия «латентные» переменные. Для исследования латентных переменных используются латентные модели или латентный структурный анализ (ЛСА). Это достаточно широкий класс моделей, которые нашли свое применение в различных областях, в том числе, при решении задач сегментирования.
Анализ латентной структуры (от лат. Latentis – скрытый, невидимый) – это статистический анализ эмпирических данных, позволяющий по ответу респондентов на некоторое множество вопросов выявить их распределение по некоторому скрытому (латентному) признаку. Этот признак нельзя измерить непосредственно, но использованное множество вопросов позволяет зафиксировать различные его проявления. Метод предложен известным американским социологом Полом Лазарсфельдом.
Суть модели, предложенной Лазарсфельдом, сводилась к следующему. Предполагается, что существует некоторая латентная переменная, которая объясняет внешнее поведение респондентов. Это поведение можно объяснить, анализируя ответы каждого человека на определенные дихотомические вопросы анкеты. Латентная переменная номинальна, число ее значений заранее известно исследователю. Объясняющая способность латентной переменной обусловливается тем, что именно она служит причиной наличия связи между наблюдаемыми переменными [4].
В основе классического латентного структурного анализа, лежит фундаментальная аксиома Лазарсфельда локальной независимости: при фиксации значения латентной переменной связи между наблюдаемыми переменными исчезают.
Подсововокупности респондентов с одинаковыми значениями латентной переменной образуют латентные классы.
Различают несколько типов латентных моделей: модели для непрерывной латентной переменной; модели для дискретной латентной переменной; модели для дихотомических признаков.
Рассмотрим общую модель латентного структурного анализа для дискретной латентной переменной, поскольку в анкетных опросах чаще имеют дело именно с такими признаками.
Будем считать, что латентная переменная является прерывной, а респонденты расположены в дискретных точках этой переменной – классах.
Пусть имеется m классов латентной переменной a и n дихотомических вопросов. Обозначим:
![]() – вероятность ответить положительно
на i-й вопрос (доля тех, кто
ответил положительно на i-й
вопрос)
– вероятность ответить положительно
на i-й вопрос (доля тех, кто
ответил положительно на i-й
вопрос)
![]() – вероятность ответить положительно
на
– вероятность ответить положительно
на ![]() i-й и j-й
вопросы одновременно.
i-й и j-й
вопросы одновременно.
![]() – вероятность ответить положительно
на i, j, к-й вопросы.
– вероятность ответить положительно
на i, j, к-й вопросы.
![]() – вероятность ответить отрицательно
на i-й вопрос и положительно на j-й и k-й
вопросы
– вероятность ответить отрицательно
на i-й вопрос и положительно на j-й и k-й
вопросы
![]() – доля респондентов,
попавших в класс m.
– доля респондентов,
попавших в класс m.
![]() – вероятность ответить положительно на i-й вопрос при условии попадания в класс m.
– вероятность ответить положительно на i-й вопрос при условии попадания в класс m.
В соответствии с формулой полной вероятности и аксиомой локальной независимости, составим основные расчетные уравнения:
![]() , (7)
, (7)
![]() , (8)
, (8)
где a=1,…, m, а s – набор индексов.
Приведем пример системы уравнений для m=2, n=2
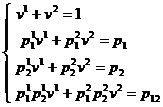 , (9)
, (9)
где ![]() – известны,
– известны, ![]() –
не известны.
–
не известны.
В общем
виде модели латентных классов число уравнений – ![]() ,
а число неизвестных параметров – m(n+1).
Очевидно, что для того, чтобы система уравнений имела решения, необходимо,
чтобы число неизвестных не превосходило число уравнений, т.е.
,
а число неизвестных параметров – m(n+1).
Очевидно, что для того, чтобы система уравнений имела решения, необходимо,
чтобы число неизвестных не превосходило число уравнений, т.е. ![]() .
.
Преимуществом латентного структурного анализа по сравнению с кластерным анализом является то, что этот метод позволяет включать в анализ переменные, измеренные в разных шкалах.
Одним из подходов к оценке латентных переменных является использование модели Раша.
Измерения с помощью модели Раша – это процесс трансформации исходных данных тестового вида в интервальную шкалу натуральных логарифмов. Для вычисления латентных переменных в модели Раша вводится понятие «логит».
Логит – это условная единица, легко переводимая в любую другую шкалу. В виду того, что шкала Раша интервальная, это позволяет использовать большое количество различных процедур статистического анализа. Помимо этого, в интервальной шкале нулевая точка отсчета (0) не зафиксирована, поэтому показатели в логитах переводятся в другую систему показателей, например, баллов при помощи линейных преобразований. А за точку отсчета в системе логитов наиболее уместно принять среднее значение показателей наблюдаемых переменных.
Первоначально модели Раша были использованы для анализа знаний при тестировании. В настоящее время область применения моделей распространилась и на другие объекты. Например, аппарат моделей Раша может быть применен для структурного анализа данных анкет, включающих вопросы, характеризующие толерантность к различным социально-экономическим процессам. Толерантность может выражаться в выборе ответов из списка:
– сильное согласие (конечно, да);
– слабое согласие (скорее да, чем нет);
– слабое несогласие (скорее нет, чем да); сильное несогласие (конечно, нет).
Основным уравнением для политомической модели Раша (переменные варьируются более чем на двух уровнях) является уравнение:
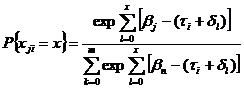 (10)
(10)
где x – градация индикаторной переменной (варьируются от 0);
![]() –
оценка j-го респондентом для i-го индикатора (пункт опросника);
–
оценка j-го респондентом для i-го индикатора (пункт опросника);
![]() –
вероятность выбора j-ым
респондентом градации x для i-го индикатора;
–
вероятность выбора j-ым
респондентом градации x для i-го индикатора;
![]() – месторасположение j-го респондента на шкале «эффективность
социально-экономической толерантности» (измеряется в логитах);
– месторасположение j-го респондента на шкале «эффективность
социально-экономической толерантности» (измеряется в логитах);
![]() –
месторасположение i-го
индикатора на той же шкале;
–
месторасположение i-го
индикатора на той же шкале;
![]() –
относительный оценка l-ой градации;
–
относительный оценка l-ой градации;
![]() –
индексная переменная, которая последовательно принимает все варианты ответов на
индикативные вопросы.
–
индексная переменная, которая последовательно принимает все варианты ответов на
индикативные вопросы.
Эта модель позволяет измерить в одной и той же шкале (в логитах) уровень толерантности и информативность пунктов опросника [7].
Далее рассмотрим несколько, относительно, новых методов сегментирования.
Один из таких методов представлен в работе [8]. Этот метод основан на применении теории графов.
Рассматриваемая
математическая модель сегментации рынка услуг базируется на 3-дольном
3-однородном гиперграфе ![]() . Вершины первой доли, т.е.
. Вершины первой доли, т.е. ![]() , взаимно однозначно соответствуют элементам
множества предоставляемых предприятием или группой предприятий услуг. Каждая
вершина второй доли
, взаимно однозначно соответствуют элементам
множества предоставляемых предприятием или группой предприятий услуг. Каждая
вершина второй доли ![]() однозначно соответствует
некоторому элементу из множества потребителей, классифицированного по демографическим
признакам. Вершины третьей доли
однозначно соответствует
некоторому элементу из множества потребителей, классифицированного по демографическим
признакам. Вершины третьей доли ![]() взаимно однозначно
соответствуют элементам множества потребителей, классифицированного по признаку
«уровень доходов»: низкий, ниже среднего, средний, выше среднего, высокий,
элит-класс. Для построения множества ребер
взаимно однозначно
соответствуют элементам множества потребителей, классифицированного по признаку
«уровень доходов»: низкий, ниже среднего, средний, выше среднего, высокий,
элит-класс. Для построения множества ребер ![]() рассматриваются всевозможные тройки
вершин
рассматриваются всевозможные тройки
вершин ![]() – такие, что
– такие, что ![]() . Всякую такую тройку называют
допустимой, если услуга
. Всякую такую тройку называют
допустимой, если услуга ![]() может быть приемлема для
потребителей данного уровня доходов
может быть приемлема для
потребителей данного уровня доходов ![]() и для данной демографической
категории
и для данной демографической
категории ![]() . Множество всех ребер
. Множество всех ребер ![]() определяется как множество всех допустимых
троек
определяется как множество всех допустимых
троек ![]() ,
, ![]() ,
, ![]() .
.
В
гиперграфе ![]() допустимым решением рассматриваемой задачи сегментации
рынка услуг является всякий такой его подгиперграф
допустимым решением рассматриваемой задачи сегментации
рынка услуг является всякий такой его подгиперграф ![]() ,
, ![]() , в котором каждая компонента связности
представляет собой простую звезду с центром в вершине
, в котором каждая компонента связности
представляет собой простую звезду с центром в вершине ![]() . Через
. Через ![]() обозначим множество всех допустимых
решений задачи покрытия гиперграфа G
звездами. Например, одно из таких решений представлено на рис. 1.
обозначим множество всех допустимых
решений задачи покрытия гиперграфа G
звездами. Например, одно из таких решений представлено на рис. 1.
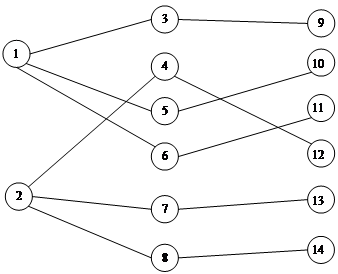
Рис. 1. Допустимое покрытие графа звездами
Для численной оценки качества допустимых решений каждому
ребру ![]() гиперграфа
гиперграфа ![]() приписываются три веса
приписываются три веса ![]() , которые представляют собой
экспертные оценки. В качестве весов могут быть: мощность услуги в данном
позиционировании, ожидаемая устойчивость данного позиционирования, и другие. Качество допустимых решений
этой задачи оценивается с помощью векторной целевой функции (11).
, которые представляют собой
экспертные оценки. В качестве весов могут быть: мощность услуги в данном
позиционировании, ожидаемая устойчивость данного позиционирования, и другие. Качество допустимых решений
этой задачи оценивается с помощью векторной целевой функции (11).
![]() (11)
(11)
В последнее время все большее распространение находит метод сегментирования основанный на коллаборативной фильтрации [10].
В общем виде алгоритм коллаборативной
фильтрации можно описать так: существует множество
пользователей ![]() и
множество объектов
и
множество объектов ![]() . Каждый пользователь
имеет список оцененных им объектов. Оценки могут принадлежать разным шкалам от
1 до 10, от 1 до 5 и т.д., а также разным типам шкал: порядковой или относительной.
Если пользователь
. Каждый пользователь
имеет список оцененных им объектов. Оценки могут принадлежать разным шкалам от
1 до 10, от 1 до 5 и т.д., а также разным типам шкал: порядковой или относительной.
Если пользователь ![]() желает получить
рекомендацию (или прогноз своей оценки на неоцененный им объект), то по
известным оценкам устанавливаются ближайшие по предпочтениям (или по оценкам на
одни и те же объекты) пользователи к множеству
желает получить
рекомендацию (или прогноз своей оценки на неоцененный им объект), то по
известным оценкам устанавливаются ближайшие по предпочтениям (или по оценкам на
одни и те же объекты) пользователи к множеству ![]() . Далее алгоритм выдает
рекомендации пользователю
. Далее алгоритм выдает
рекомендации пользователю ![]() (или
рассчитывает прогнозную оценку на объект), исходя из оценок ближайших к
(или
рассчитывает прогнозную оценку на объект), исходя из оценок ближайших к ![]() пользователям
по их предпочтениям.
пользователям
по их предпочтениям.
Собственная концепция сегментирования на основе стоимости была предложена Институтом оценки бизнеса компании IBM (рис. 2) [9].

Рис. 2. Принцип сегментирования, использованный институтом оценки бизнеса компании IBM
В туристском бизнесе широкое распространение нашли методы сегментации рынка по психографическим признакам. Сегментация рынка по психографическим признакам – это процесс разделения всех покупателей рынка на однородные группы по таким критериям, как: ценности, убеждения, мотивация к покупке товара и тип личности.
Сегментирование по психографическим признакам основывается на теории типологического анализа.
Типологический анализ – метаметодика анализа данных, совокупность методов изучения социального феномена, позволяющих выделить социально значимые, внутренне однородные, качественно отличные друг от друга группы эмпирических объектов, характеризующиеся типообразующими признаками, природа которых различна, и интерпретируемые как носители различных типов существования феномена [11].
Типологический анализ, в основном, базируется на анализе качественных данных. По мнению В.А. Ядова, качественные методы позволяют глубже понять изучаемое явление и предложить множественную интерпретацию [12].
В мировой литературе утвердилось понятие «качественные методы исследования», которые иногда называют «мягкими» в отличие от «количественных» и «жестких». В определенном смысле можно говорить также о неформализованных или слабо формализованных подходах в сравнении с жестко формализованными.
Основанием типологии служит совокупность суждений (утверждений) о близости (схожести, похожести) объектов, носителей информации об изучаемых социальных феноменах (явлениях, процессах).
Предметом типологии является совокупность основных характеристик социального феномена, ответственная за отнесение эмпирических объектов к однотипной группе.
Рассмотрим некоторые термины, которые используются в типологическом анализе.
Тип (анг. type) – вид, форма существования социальных феноменов в науке или в повседневной жизнедеятельности людей. Тип – сущность, знание о которой всегда относительно. Имеет три условных значения в смысле – типовой, типологический, типический.
Типологический – в типологическом анализе: особенный, общий, объединяющий.
Типизация (анг. typization) – конструирование людьми социальной реальности на основе придания окружающим ярлыков, спонтанная классификация.
Типологизация (анг. typologization) – процедура систематизации знаний об изучаемых феноменах либо для введения (задания) типов, либо для поиска знаний о типах. Типологизация служит для конструирования типов.
Типология (анг. typology) – Совокупность типов, результат их конструирования. Способ конструирования типов.
Типообразующий признак — характеристика, свойство социальных феноменов, на основе которых либо конструируются типы, либо формулируются гипотезы об их существовании. Типообразующий признак – это концептуальная переменная.
Существует несколько подходов к решению проблемы неструктурированных или неформализованных данных. В саму природу нечисловой информации заложена возможность использования для ее обобщения и структуризации типологический анализ. «При всей уникальности действующего индивида большая часть его индивидуальных смыслов типична, т. е. обладает общностью с другими людьми» [1]. Одной из основных задач является разработка алгоритма построения типологий таким образом, чтобы преодолеть субъективность исследователя, не упустив при этом важную информацию. Алгоритмы предполагают применение сжатия и структурирования информации так, чтобы она сохранила свойства исследуемого объекта.
Можно выделить три подхода построения типологий:
– концепция типологических операций А. Бартона и П.Ф. Лазарсфельда;
– анализ структуры У. Герхардта;
– типологический анализ У. Кукартца.
Первый подход основан на использовании «типологических операций»: редукции, субструкции и трансформации. Через определение признаков и степеней их выраженности строится пространство свойств, которые лежат в основе типологии. Используя графическую или табличную формы представления данных, определяются все возможные комбинации и все потенциальные типы. Все типы связываются на одном пространстве. Комбинации признаков могут быть сокращены. Субструкция выявляет само пространство признаков, лежащее в основе типологии, которое может трансформироваться при интерпретации сконструированных типов. Несмотря на то, что данный подход был предложен для конструирования типов в исследованиях количественной стратегии, он имеет центральное значение для обобщения нечисловой информации.
Второй и третий подходы используют те же основные типологические операции, пытаясь при этом преодолеть его главный недостаток: определение критериев отбора признаков для анализа данных. В основе второго подхода лежат «идеальные типы», которые служат базисом для анализа информации, полученной в ходе исследования. На первом этапе проводится сравнение случаев через их реконструкцию, чтобы выявить их особенности. Это привносит в исследование прозрачность процесса обобщения и его результатов. На втором этапе исследуемые случаи группируются с помощью их сопоставления. Эти приемы в целом соответствуют «концепции типологических операций» и позволяют узнать все потенциально возможные комбинации признаков. На последнем этапе выявляются и объясняются смысловые связи внутри и между полученными группами. Для этой цели был разработан анализ структуры и процесса, состоящий из двух шагов обобщения. Главными недостатками данного подхода являются трудность абстрагироваться от субъективных представлений исследователя при обобщении данных и отсутствие алгоритма проверки сконструированных типов.
Типологический анализ в данном подходе имеет ряд особенностей по сравнению с другими методами обобщения качественных данных. В процессе работы абстрагируются от каждого отдельного исследуемого случая и получают типичное событие, как результат упорядоченных фаз секвенции. «Структурная герменевтика», наоборот, понимает материал в его единичности, неотделенности от каждого конкретного исследуемого случая. Типологический анализ находится в точке пересечения между индивидуальной историей и общепринятой. Во втором подходе исследуемые случаи сохраняются по возможности в своей целостности, в третьем подходе при анализе отдельных случаев и их сравнении используется тематическое обобщение.
Третье направление в полной мере нельзя считать отдельным подходом. Это «инструмент, построенный для целей выражения методологических взглядов М. Вебера» [3]. При разработке инструментов типологического анализа (программных средств) предпринимается попытка соединить в исследовании различные способы типологизации нечисловой информации с учетом их достоинств и недостатков.
Известные социологи Н. Филдинг и Р. Ли в предметной области инструментальных средств анализа качественных данных предложили использовать специальный термин «компьютерный, но ассистируемый анализ качественных данных» (Computer Assisted Qualitative Data AnalysiS, CAQDAS). Современный компьютерно-ассистируемый анализ качественных данных является методологической исследовательской областью, объединяющей ученых многих стран. Ассистируемый анализ представлен множеством компьютерных пакетов, в том числе: Atlas.ti, MAXQDA, NVivo, xSight, Qualrus, Ethnograph и др. Эти пакеты представляют собой класс компьютерных программ, которые включают в свою архитектуру специальные структуры, называемые функциями кодирования и реконструирования качественных, нечисловых данных (coding and retrieval functions). Функции кодирования и реконструирования данных (ФКР) представляют собой компьютерный инструмент (tool), используемый в человеко-машинном режиме и ассистирующий пользователю при изучении данных, представленных в так называемых нечисловых форматах. В основе ассистирования лежит аппарат аналитических переобозначений, называемых кодами, введение и связывание которых между собой осуществляется самим пользователем. Более подробный анализ методологических разработок компьютерного инструментария анализа качественных данных представлен в работе [3].
Отмечая широкие возможности зарубежных компьютерных инструментальных средств анализа качественных данных нельзя не отметить, что они не нашли своего распространения не только у отечественных ученых, занимающихся проблемами сегментирования рынка, но и у отечественных социологов. Эти средства имеют несколько другую направленность и больше предназначены для решения гуманитарных и лингвистических задач.
В работах [5, 6] представлена методология анализа качественных данных, которые собираются с целью исследования рынков и, в частности, туристского рынка. Методология включает достаточно простые в применении компьютерные программные инструменты, которые могут быть использованы в рамках компьютерной среды EXCEL, которая является наиболее распространенной среди отечественных исследователей рынков. Предложенная методология основывается на представлении данных в форме «термов».
Термом
называется символьное выражение: ![]() , где t – имя
терма, называемая функтор или «функциональная буква», а
, где t – имя
терма, называемая функтор или «функциональная буква», а ![]() – термы, структурированные или
простейшие. Для формального описания термов в работе было введено новое понятие
– составной признак.
– термы, структурированные или
простейшие. Для формального описания термов в работе было введено новое понятие
– составной признак.
Предложенную методологию анализа данных, используемых при сегментировании, необходимо рассматривать не столько как учение о методах, сколько как учение о взаимодействии методов между собой на разных классах исследовательских практик анализа данных. Структурно эта методология включает приемы и методы сбора и измерения информации, а также математические методы.
Использование комбинации количественных и качественных методов часто является наилучшим решением проблемы сегментирования рынка. Различные методы дополняют и контролируют друг друга, ограничения одного метода уравновешиваются ограничениями другого. Такие свойства называют комплиментарностью и триангуляцией.
Комплементарными называют несходные или даже противоположные теории, концепции, модели и точки зрения, отражающие различные взгляды на действительность.
Триангуляция – это возможность использования несколько источников информации. В анализе рынка можно выделить несколько типов триангуляции: триангуляция данных; триангуляция исследователей; триангуляция методов; триангуляция теорий.
Рецензенты:Латкин А.П., д.э.н., профессор, директор института подготовки кадров высшей квалификации ВГУЭС г. Владивосток;
Ембулаев В.Н., д.э.н., профессор кафедры Математики и моделирования ВГУЭС, г. Владивосток.
Библиографическая ссылка
Мартышенко Н.С., Грачева В.В. СОВРЕМЕННЫЕ МЕТОДЫ И ИНСТРУМЕНТЫ СЕГМЕНТИРОВАНИЯ ПОТРЕБИТЕЛЬСКИХ РЫНКОВ // Современные проблемы науки и образования. 2014. № 6. ;URL: https://science-education.ru/ru/article/view?id=16405 (дата обращения: 02.07.2025).