



Адаптивный алгоритм обучения, разработанный профессором Л.А. Растригиным, [4] по праву можно назвать одной из ключевых посылок к созданию мультилингвистической адаптивно-обучающей технологии [1]. Ввиду специфики информационно-терминологической базы [3], оригинальный адаптивный алгоритм обучения был модифицирован с учетом ассоциативных связей, возникающих между языковыми аналогами в процессе обучения. Согласно этой модификации, был изменен механизм вычисления скоростей забывания, при этом последовательность алгоритмических шагов не изменилась [1].
Одним из основных аспектов МЛ-технологии является установление однозначных ассоциаций между терминами различных языков. Под ассоциацией здесь следует понимать связь между двумя психическими элементами, возникающую в результате опыта и обусловливающую при актуализации одного элемента связи проявление другого элемента. К сожалению, МЛ-технология устанавливает ассоциативные связи только между языковыми аналогами одного и того же понятия, не затрагивая при этом ассоциации, возникающие между лексемами в рамках одного языка.
В работе [2] были сформулированы основные положения методики обучения иностранной лексике на основе лексически связанных компонентов (ЛСК-методика). Данная методика разрабатывается в рамках МЛ-технологии и делает возможным организованное построение систем лексических связей внутри целевого языка в процессе обучения. Одним из обязательных условий применения ЛСК-методики является реорганизация структуры информационно-терминологического базиса (ИТБ), который в данном случае рассматривается как совокупность лексически связанных компонентов (ЛС-компонентов). Это приводит к неоднородности скоростей забывания, что требует пересмотра и модификации адаптивного алгоритма обучения для данной методики.
Методика обучения иностранной лексике на основе лексически связанных компонентов.
Методика обучения строится на совместном применении двух алгоритмов:
-
адаптивного алгоритма обучения;
-
алгоритма построения внутриязыковых ассоциативных полей.
Алгоритм построения внутриязыковых ассоциативных полей состоит в последовательной подаче к изучению элементов ЛС-компонента [5]. Последовательность такова:
-
основная лексема – перевод, подсказка на иностранном языке (в рамках МЛ-технологии);
-
связанная лексема – перевод, подсказка на иностранном языке (в рамках МЛ-технологии);
-
лексическое сочетание основной и связанной лексем – перевод сочетания, подсказка на иностранном языке (языковой аналог именно лексического сочетания, но не лексем по отдельности);
-
переход к следующей связанной лексеме;
-
переход к следующему лексически связанному компоненту.
Адаптивный алгоритм обучения иностранной лексике на основе лексически связанных компонентов.
При использовании данной методики адаптивный алгоритм обучения [3] будет в значительной степени модифицирован. Исходя из измененной нами структуры ИТБ, в качестве основного элемента обучающей информации логично брать не термин, как это было прежде, но лексически связанный компонент. Это само по себе вызывает ряд вопросов, таких, например, как: «Каким образом поведет себя алгоритм, если часть компонента забудется, а часть нет?».
В дальнейшем мы подробно рассмотрим адаптивный алгоритм обучения именно с точки зрения изменения базисного информационного компонента. А пока обратимся к другой не менее важной особенности применения выбранной нами методики обучения. Она заключается в том, что основные лексемы ЛС-компонентов будут заучены гораздо лучше, чем их связанные лексемы. Это обуславливается ассоциативными механизмами памяти человека, а именно тем, что при актуализации одного понятия актуализируется другое, ассоциативно связанное с ним; вместе с этим выбранная нами методика такова, что наибольшее количество ассоциативных связей приходится именно на основные лексемы. Необходимо заметить, что подобного эффекта простым повторением лексем добиться невозможно, так как в этом случае ассоциативные механизмы памяти оказываются незадействованными.
При таком подходе скорость забывания лексем будет не однородна для всех элементов ИТБ. А поскольку «классический» адаптивный алгоритм обучения построен именно на однородных скоростях забывания, возникает необходимость в существенной его модификации для адекватного отражения реальной картины знаний обучаемого в каждый момент времени обучения.
Рассмотрим разработанную нами модификацию адаптивного алгоритма обучения с учетом сформулированных ранее проблем.
Состояние обучаемого на n-ом сеансе описывается вектором вероятностей незнания каждого из элементов ОИ:
Yn=Pn=(p1n, p2n, ..., pNn), (1)
где pin - вероятность незнания i-го элемента в n-й момент времени tn.
Очевидно, что в момент заучивания порции ОИ на n-м сеансе ученик знает элементы данной порции с вероятностью единица, т.е. вероятности незнания элементов из Un в момент tn равны нулю. Однако с течением времени происходит их забывание. Вероятности незнания элементов ОИ изменяются по правилу
pin = pi(tin) = 1-e- , (2)
где ain - скорость забывания i-го элемента ОИ на n-м сеансе с учетом его связи с элементами ранее изучавшихся иностранных терминологий;
tin - время с момента последнего заучивания i-го элемента ОИ.
Поскольку одним из путей формирования ИТБ для данной методики является нейросетевой анализ языкового материала, то скорость забывания можно откорректировать, учтя повторяющиеся n-граммы, как это было сделано в работе [5].
ain=![]() , (3)
, (3)
где bin – скорость забывания i-го элемента ОИ на n-м сеансе; ![]() – коэффициент лексической однородности, определяемый при формировании мощностного словаря:
– коэффициент лексической однородности, определяемый при формировании мощностного словаря:
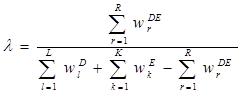 , (4)
, (4)
где wlD и wkE – все возможные сочетания символов, входящих в лексему, в виде n-гpамм всех доступных уровней (wlD – n-граммы немецкой лексемы, wkE – n-граммы английской лексемы), wrDE – однородные n-граммы, одновременно входящие в лексемы обоих языков, т.е. рассчитывается отношение общего количества n-грамм всех уровней, образующих лексемы исследуемых языков к количеству одинаковых n-грамм, входящих в лексемы.
Теперь проведем коррекцию скоростей забывания с учетом устанавливаемых внутриязыковых ассоциативных связей.
ain=![]() , (5)
, (5)
где (1-pik) – вероятность знания k-ого элемента ОИ, который лексически связан (т.е. порождает ассоциацию) с i-ым элементом ОИ.
![]() ik – абсолютная частота сочетания i–ой и k–ой лексем, отражает силу ассоциативной связи, к которой, в конечном итоге, стремится алгоритм за счет критерия
ik – абсолютная частота сочетания i–ой и k–ой лексем, отражает силу ассоциативной связи, к которой, в конечном итоге, стремится алгоритм за счет критерия 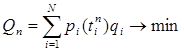
Или без учета повторяющихся n-грамм:
ain=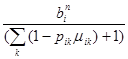 , (6)
, (6)
Таким образом, мы учитываем внутриязыковые лексические связи, возникающие в процессе обучения, а также избавляемся от необходимости разделять скорости забывания по принадлежности к основным или связанным лексемам. При этом скорости забывания основных лексем будут в значительной степени ниже скоростей забывания связанных лексем. Это соответствует методике обучения, но не соответствует принципам формирования порций обучающей информации, так как в данном случае приоритет основных лексем (а их нужно запомнить в первую очередь) уменьшится. Данное противоречие будет решено при рассмотрении принципов формирования обучающей информации.
Скорость забывания каждого элемента уменьшается, если этот элемент выдается обучаемому для запоминания, и не изменяется, если он не заучивается:
ain+1=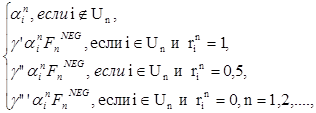 (7)
(7)
где αi1 - начальное значение скорости забывания, оцениваемое методом максимального правдоподобия, 0<αi1<1, (i = 1, 2, ..., N);
γ', γ", γ"' - параметры коррекции скоростей забывания, характеризующие индивидуальные особенности памяти обучаемого, оцениваемые методом максимального правдоподобия, 0<γ'<1, 0<γ"<1, 0<γ"'<1.
![]() – ассоциативный параметр, выражающий степень связи элементов обучающей информации на иностранных языках согласно выражению (12). Для примера взят случай изучения немецкой (G) лексики при подсказках на английском (E) и русском (N) языках.
– ассоциативный параметр, выражающий степень связи элементов обучающей информации на иностранных языках согласно выражению (12). Для примера взят случай изучения немецкой (G) лексики при подсказках на английском (E) и русском (N) языках.
![]()
![]() ; (8)
; (8)
где vn – скорость восприятия информации обучаемым; n‑ количество сеансов обучения;
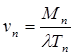 ; (9)
; (9)
где Mn – объем очередной порции обучающей информации; Tn – продолжительность n-го сеанса обучения; 0<l<1 – коэффициент потери информации во время ее поступления в память.
Rn=(r1n, ..., rMnn) - множество ответов обучаемого на тесты:
 (10)
(10)
Критерием качества обучения Qn необходимо выбрать такой, который характеризует уровень обученности обучаемого. Для рассматриваемой задачи данный уровень характеризуется вероятностью незнания элемента ОИ, наугад выбранного из текста:
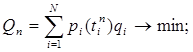 (11)
(11)
где pin(tin) - вероятность незнания i-го элемента ОИ; qi - относительная частота, выражающая долю лексической единицы в тексте, подвергшемуся статистической обработке при составлении частотного словаря, 0<qi <1,
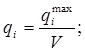 (12)
(12)
где qimax=max q{qi1, qi2,..., qin} - абсолютная частота появления лексической единицы в тексте; qi1, qi2,..., qin - частоты из мультилингвистического словаря.
Результатом решения данной задачи является локально-оптимальная порция ОИ U*n, которая выдается обучаемому на n-м сеансе обучения.
Для минимизации значения Qn к концу сеанса обучения естественно в порцию U*n включать элементы ОИ, имеющие наибольшее значение произведения pi(tin)qi, так как в результате их запоминания это произведение становится равным нулю и тем самым наибольшим образом снижает значение Qn.
Таким образом, для обеспечения оптимального значения Qn к концу n-го сеанса обучения необходимо найти Mn максимальных членов суммы в критерии, индексы которых и определят очередную порцию ОИ, выдаваемую ученику для запоминания. Процедура поиска индексов для терминов записывается следующим образом:
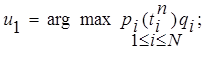
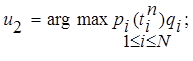 (13)
(13)
![]()
![]()
где arg max {ai}=i* - индекс i*ÎU максимального значения ai,, т.е. ai*=max ai, и, таким образом, {u1, ..., uMn}=U* - та порция ОИ, которая выдается для заучивания на n-м сеансе.
Но с учетом применения методики обучения на основе лексически связанных компонентов, за ui, будем брать не термин, а:
- лексическое сочетание основной и связанной лексемы, если наибольший вес приобрела связанная лексема;
- лексически связанный компонент, если наибольший вес приобрела основная лексема.
Основная лексема будет включена в порцию ОИ, если туда будет включен хотя бы один связанный с ней элемент ЛС-компонента. Таким образом, решается противоречие между относительно низкими скоростями забывания основных лексем и принципами формирования порций обучающей информации. Не менее важно, что при таком подходе не нарушается, а закрепляется «как есть» система внутриязыковых ассоциативных понятий, сформированная в процессе обучения.
Объем порции ОИ зависит от Tn – продолжительности n-го сеанса обучения, или времени, отведенного на заучивание порции Un. Предполагается, что время заучивания i-го элемента прямо пропорционально вероятности его незнания, т.е. очевидно, что чем меньше вероятность незнания элемента, тем меньше времени необходимо на его заучивание. Тогда объем Mn очередной порции Un определяется из следующего соотношения:
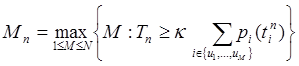 , (14)
, (14)
где k – среднее время заучивания элемента ОИ при первом его предъявлении ученику; u1, ..., uM – номера элементов ОИ, определяемых с помощью процедуры (4).
Параметр k априорно неизвестен и поэтому должен оцениваться адаптивно в процессе обучения в зависимости от времени, затрачиваемого обучаемым на выполнение порции ОИ:
![]() , (15)
, (15)
где ![]() – безразмерный коэффициент скорости адаптации, а T’n – время, затраченное учеником на заучивание Un.
– безразмерный коэффициент скорости адаптации, а T’n – время, затраченное учеником на заучивание Un.
Обучение заканчивается, когда Qn достигает требуемого уровня обученности d. Число сеансов обучения n, за которое достигается Qn ≤ d, определяет продолжительность обучения.
В целом, разработанный нами адаптивно-обучающий алгоритм не только адекватно оценивает скорости забывания лексем, но и поддерживает целостность систем ассоциативных связей на этапе формирования порций ОИ. Это в конечном итоге приводит к набору ассоциативно-связанных лексических понятий, соответствующих терминам изучаемого языка, как по силе внутренних связей, так и по абсолютной частоте в предметной области, то есть к адекватному систематизированному знанию изучаемого материала.
В данной статье рассмотрена модификация адаптивно-обучающего алгоритма МЛ-технологии для использования методики обучения на основе лексически связанных компонентов.
Сформулированы и решены следующие задачи: задача о базисном информационном компоненте адаптивно-обучающего алгоритма; задача о неоднородности скоростей забывания элементов ЛС-компонента; задача о формировании порций обучающей информации.
Рецензенты:
Антамошкин А.Н., д.т.н., профессор, профессор кафедры системного анализа и исследования операций ФГБОУ ВПО «Сибирский государственный аэрокосмический университет» (Министерство образования и науки РФ), г. Красноярск.
Кузнецов А.А., д.ф.-м.н., доцент, директор международной высшей школы бизнеса ФГБОУ ВПО «Сибирский государственный аэрокосмический университет» (Министерство образования и науки РФ), г. Красноярск.
Библиографическая ссылка
Карасева М.В., Ступина А.А., Мельдер М.И. МОДИФИКАЦИЯ АЛГОРИТМА ОБУЧЕНИЯ ИНОСТРАННОЙ ТЕРМИНОЛОГИИ // Современные проблемы науки и образования. 2014. № 3. ;URL: https://science-education.ru/ru/article/view?id=13058 (дата обращения: 26.07.2026).