


Scientific journal
Modern problems of science and education
ISSN 2070-7428
"Перечень" ВАК
ИФ РИНЦ = 0,936
BINAURAL SYNTHESIS IN ART OF SOUND RECORDING AND REPRODUCTION (UPMIX AND DOWNMIX)

Преобразование многоканальных сигналов в бинауральные (downmix)
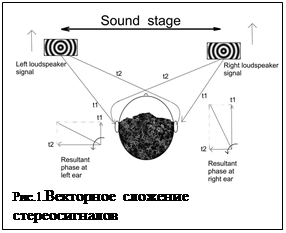
Стереосигналы в бинауральные:
Наиболее популярной формой записи в настоящее время по-прежнему остается стереозапись, принципы организации которой были предложены A. Blumlein’ом еще в 1928 г.
В ее основе лежит или общая запись двумя микрофонами, совмещенными или разнесенными (используемые в настоящее время системы стереомикрофонов достаточно разнообразны – АВ, ORTF, DIN, NOS, MS, XY и др.), или точечная запись несколькими микрофонами с последующим микшированием в два канала.
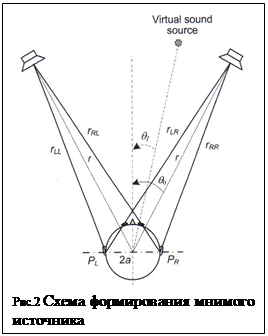
При воспроизведении через два громкоговорителя, происходит векторное сложение сигналов на обоих ушах (так называемое «сложение фазоров») рис.1. В случае если сигналы коррелированны (коэффициент корреляции не менее 0.15) происходит слияние сигналов в единый мнимый стереообраз (КИЗ – кажущийся источник звука), расположенный на линии между громкоговорителями [2,6,7]. При векторном сложении сигналов от двух громкоговорителей с разной амплитудой образуются суммарные векторы на каждом ухе с определенной разницей по фазе Δφ, мозг интерпретирует эту разницу как разницу во времени ITD=Δφ/2πf, необходимую ему для локализации источника звука на низких частотах, помещая КИЗ в разные точки на линии между громкоговорителями. Если сигналы имеют одинаковые амплитуды, КИЗ располагается в центре. На высоких частотах (выше 1500Гц) к разнице по интенсивности между стереоканалами добавляется разница по интенсивности между левым и правым ухом за счет дифракции на голове и КИЗ сдвигается от центральной точки (стереообраз расширяется). Поскольку музыка является широкополосным сигналом, то высокочастотные компоненты каждого инструмента воспринимаются под несколько более широким углом, чем на низких частотах, эта проблема давно обсуждается в литературе (для решения предложены различные варианты [5]). Для размещения источников звука в разных точках между ГГ используется в основном амплитудное панорамирование, теория которого достаточно подробно разработана как для стерео-, так и для многоканального воспроизведения [12]. В частности, для стереосигналов используется «закон синуса» для расчета положения мнимого источника в зависимости от разности уровня сигналов на двух громкоговорителях:
sinθI=![]() sinθ0
sinθ0
где θ0 – угол между громкоговорителями, θI – угол между осью и направлением на мнимый источник, L и R – амплитуды звукового давления на левом и правом громкоговорителе (рис. 2). Следует отметить, что амплитудное панорамирование обеспечивает возникновение КИЗ в пределах угла расположения ГГ (относительно точки расположения слушателя) порядка 60 град. При этом зона расположения слушателя (зона стереоэффекта-sweetpot) также очень ограничена [2]. При воспроизведении стереосигналов через стереотелефоны имеет место латерализация, т.е. размещение источника звука внутри головы, поскольку векторного сложения сигналов на ушах не происходит, амплитудная разница между стереосигналами не превращается в фазовую (временную разность), и мозгу не хватает информации для внешней локализации источника. Кроме того, расстояние между микрофонами обычно больше, чем расстояние между ушами, поэтому разница по времени между сигналами на ГГ не соответствует натуральной. Отсутствует обработка сигналов на ушных раковинах и голове, что не дает информации о высоте и глубине расположения источника. Кроме того, запись диффузного звука микрофонами в первичном помещении не соответствует их записи на голове слушателя (или на ИГ), поскольку корреляция между диффузными левыми и правыми сигналами не зависит от частоты, а при записи на голове она является частотно-зависимой и это играет существенную роль в оценке пространственных свойств помещения [8]. Все это приводит к ненатуральности звучания и размещению КИЗ внутри головы.
Для создания внешней локализации звукового источника при прослушивании стереозаписей через стереотелефоны используются в настоящее время методы бинаурального синтеза, позволяющие реализовать перевод стереосигналов в бинауральные.
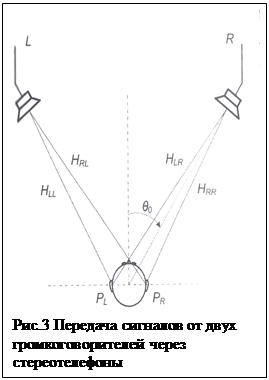
Для этого перевода стандартный способ заключается в том, что для каждого из двух сигналов от громкоговорителей L и R реализуется фильтрация четырьмя передаточными HRTF, соответствующими прямым и перекрестным сигналам (рис. 3), т.е. слушатель в стереотелефонах получает такие же сигналы, как и при естественном прослушивании стереогромкоговорителей без телефонов. Следовательно, сигналы EL и ЕR, поступающие на стереотелефоны, должны быть связаны с сигналами от громкоговорителей следующим соотношением:
![]() =
=![]()
![]() (3)
(3)
При этом КИЗ выносится из головы, однако экстернализация получается не полной (мнимый источник часто располагается на поверхности головы, возможны ошибки типа «фронт-тыл» и др.) [6]. Для более реалистичного воспроизведения необходимо учесть реверберацию во вторичном помещении прослушивания, которая оказывает влияние на прослушивание стереосигналов через громкоговорители. Для этого надо заменить в выражении (3) передаточные функции HRTF (измеряемые в заглушенной камере) на BRTF измеренными в помещении прослушивания (или произвести свертку сигнала с импульсными функциями BRIR, что эквивалентно) [4]. Следует отметить, что вводить влияние вторичного помещения необходимо достаточно осторожно, поскольку это может придти в противоречие с реверберацией первичного помещения, записанной при создании стереофонограммы. При прослушивании через ГГ слушатель видит помещение, в котором он находится и может отделить влияние одного от другого. Следует отметить, что как и в бинауральной стереофонии желательно для уменьшения искажений тембра производить калибровку стереотелефонов (см. выше) [6].
Примерами коммерческих процессорных систем для прослушивания стереосигналов через телефоны с выносом звукового образа из головы могут служить BAP Binaural Audio Processor by AKGA coustics and the Dolby Headphone [13].
При этом мнимый источник будет располагаться в переднем полупространстве, появляется корректное ощущение расстояния до источника и другие свойства, присущие живой записи.
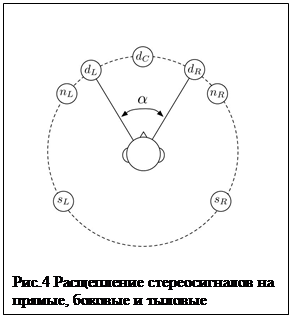
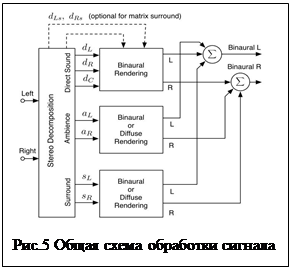
Для того чтобы из стереофонической записи получить полностью объемный бинауральный звук, в работах [8] был предложен алгоритм «расщепления» стереосигнала на три прямых, два боковых и два тыловых сигнала (рис. 4), каждый из этих сигналов обрабатывается с помощью соответствующей выбранному направлению пары HRTF (или реализуется свертка с импульсными характеристиками HRIR), как альтернативный вариант – передние три сигнала обрабатываются с помощью HRIR (т.е. по свободному полю), а остальные сигналы рассматриваются как общий диффузный звук и обрабатываются с помощью свертки с импульсными характеристиками фильтров, обеспечивающими частотно зависимую корреляцию между диффузными сигналами на левом и правом ухе, что очень важно для правильного восприятия глубины (как сказано выше, при микрофонной записи корреляция между диффузными сигналами от частоты не зависит). Общая схема обработки сигналов представлена на рис. 5. Таким образом, можно получить более широкий пространственный звуковой образ и избежать конфликта между реверберацией вторичного и первичного помещения, поскольку в данном случае через передние громкоговорители воспроизводится только реверберационный процесс первичного помещения. Субъективные экспертизы подтвердили качественно более высокий уровень пространственного звука, полученного таким методом.
Многоканальные сигналы в бинауральные (downmix)
В настоящее время широко используются для воспроизведения различные системы пространственного звука: DolbyDigital 5.1, 7.1 а также 10.2, 22.2 и пр. Все эти системы достаточно дороги, требуют большого количества высококачественных громкоговорителей, используются в достаточно «сухих» (хорошо заглушенных) больших помещениях и, следовательно, их реализация в домашних условиях проблематична.
Поэтому в настоящее время широко распространяются технологии преобразования многоканальных сигналов в бинауральные и воспроизведение их через стереотелефоны или трансаурально через два громкоговорителя (особенно для мобильных устройств и компьютеров). Обычно при воспроизведении многоканальных сигналов через телефоны сложение в два канала производится по следующему закону:
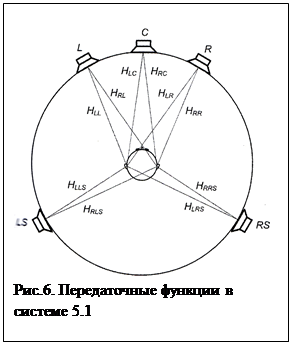
EL=L+0.707C+LS; ER=R+0.707C+RS, где L, R, C, LS, RS-сигналы от левого, правого, центрального и двух тыловых громкоговорителей (рис. 6). При этом пропадает пространственная информация, и звук локализуется внутри головы. Применение бинаурального синтеза позволяет воссоздать пространственное впечатление аналогичное тому, которое воспринимается при прослушивании реальных систем 5.1. Как показано на рис. 6, каждому положению громкоговорителя в системе 5.1 соответствует своя пара передаточных функций (которая может быть измерена на ИГ или взята из имеющихся баз данных). Если теперь сигналы от каждого громкоговорителя отфильтровать пятью парами передаточных функций, то сигналы, подаваемые на телефоны, будут иметь следующий вид:
EL=HLLL+HLCC+HLRR+HLLSLS+HLRSRS (4)
ER=HRLL+HRCC+HRRR+HRLSLS+HRRSRS
Во временной форме это соответствует операции свертки сигналов от каждого громкоговорителя с пятью парами импульсных характеристики HRIR.
Алгоритм решения уравнения (4) сложный и требует больших расчетных ресурсов, поэтому были разработаны различные упрощенные варианты, анализ которых дан в работе [6]. Данный алгоритм не учитывает влияние отражений во вторичном помещении. Обычно при реальном воспроизведении рекомендуется в соответствии с рекомендациями ITUBS 775-1 использовать помещения с малым уровнем отражений, но их учет полезен при бинауральном синтезе, т.к. улучшает вынос образа из головы, ощущение глубины и пр. Для их учета необходимо выполнить свертку сигналов от пяти громкоговорителей с соответствующими парами импульсных характеристик BRIR, измеренных или рассчитанных в заданном помещении. Существуют различные алгоритмы такого преобразования, в частности система LakeHuron, созданная фирмой LakeDSP [8], система Dolby Headphone и др. Реализация операции свертки в реальном времени не позволяет использовать слишком длинные импульсные характеристики и тем самым дает возможность моделировать только первые отражения. Поэтому поиски новых алгоритмов активно продолжаются [6].
Для преобразования в два канала с помощью бинаурального синтеза созданы программы для систем 7.1; 22.2, Амбисоник и др.[11].
Вычисление импульсных характеристик для заданного положения громкоговорителей и слушателя в помещении производится, например, с помощью программ AFMG-EASE, CATT, ODEON [3]. Для этого, как показано на рисунке 7, задаются параметры помещения (размер, форма, используемые материалы и др.), вычисляется структура звукового поля в нем и моделируются импульсные характеристики в заданных точках расположения слушателя. Затем полученные пары BRIR для пяти ГГ суммируются и подаются на два канала стереотелефонов. Необходимо при этом произвести калибровку стереотелефонов (см. выше). Кроме того, разработанные программные пакеты позволяют учесть повороты головы слушателя, для этого с помощью сенсора, регистрирующего повороты головы, пересчитываются импульсные характеристики с минимальными по времени задержками, при этом получается реальное воспроизведение, т.е. источник сохраняет свое неподвижное положение относительно помещения, т.е. при повороте головы источник остается на месте. Обычно не учитываются индивидуальные особенности BRIR, но общее пространственное впечатление оказывается сильнее этих различий. Следует отметить, что системы интерактивны, т.е. можно изменять свойства пространства и положение излучателей. Аналогичное преобразование можно сделать и для воспроизведения системы 5.1 через два громкоговорителя (аналогично принципам трансауральной стереофонии) [13], позволяя через два ГГ воспроизвести пространственный звук.
Преобразование бинауральных сигналов в многоканальные (upmix)
Запись на искусственной голове в ряде ситуаций оказывается удобней и проще, чем использование многомикрофонной записи, но поскольку наиболее распространенными системами воспроизведения являются в настоящее стереогромкоговорители и системы типа 5.1, то в ряде случаев желательно иметь возможность бинауральные записи воспроизводить через обычные системы громкоговорителей. Для решения возникающих при этом проблем разработаны специальные алгоритмы преобразования бинауральных записей в стерео или 5.1 (upmix).
Бинауральные сигналы в стерео
При прямом воспроизведении бинауральных сигналов через стереогромкоговорители сильно искажается тембр, как уже было отмечено выше из-за искажений спектральных характеристик сигналов при записи на искусственной голове. При этом стереопанорама сильно сужается [13], т.к. запись производится при близком расположении микрофонов на ИГ (20 см) (микрофоны под углом 180 градусов и с широкой характеристикой направленности, при этом, как показано в работе М. Вильямса [15], угол охвата будет составлять +/-30град). Для расширения стереообраза на низких частотах, Griesinger [13] предложил усилить разность между каналами на 15дБ на 40Гц. Тембр частично искажается и при трансауральной стереофонии, но там это компенсируется ощущением пространственности, которая при стеревоспроизведении возникает только частично. Поэтому необходимо выполнить обратное преобразование, отфильтровать (сделать свертку, если операции производятся во временной области) два стереосигнала с помощью обратных передаточных функций HRTFл-1 и HRTFпр-1, т.е. убрать эффекты дифракции на голове и ушных раковинах. При этом пространственное ощущение пропадает, звук будет локализоваться только в плоскости между ГГ (следует отметить, что поскольку функции HRTF измеряются в свободном поле, то при такой фильтрации убирается вклад головы и ушных раковин в свободном поле, т.е. в прямой звук, но не убирается влияние головы на восприятие реверберирующего сигнала в первичном помещении и поэтому через ГГ будет передаваться реверберирующий сигнал первичного поля, записанный иначе, чем двумя микрофонами при обычной стереофонии).
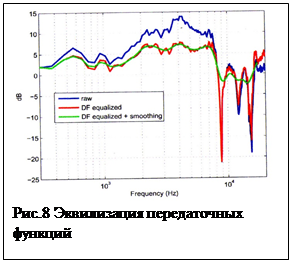
Часто используется компромиссный вариант, только эквализация (сглаживание) передаточных функций HPTF с сохранением некоторых пространственных признаков [8], при этом сигнал будет воспроизводиться через ГГ с приемлемым тембром, но ощущение пространственности в определенной степени сохранится. Эквализация может быть как по свободному полю (все HRTF должны быть отнесены (т.е. разделены) к HRTF, соответствующей осевому направлению), так и по диффузному полю, т.е. должны быть HRTF отнесены к средней кривой измеренной в диффузном поле, таким образом, выровнена АЧХ по энергии (рис. 8).
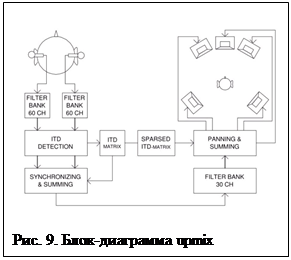
Значительный интерес представляют методы (алгоритмы) преобразования бинауральных сигналов в многоканальные (upmix). Это обусловлено тем, что в ряде ситуаций бинауральные записи сделать проще (нужна только искусственная голова), а при воспроизведении достаточно часто возникает необходимость использования систем типа Dolby 5.1 или аналогичных других, поскольку они достаточно широко используются на практике. Существуют различные алгоритмы такого преобразования, один из них приведен в диссертации финского исследователя Джулии Юкки [9]. Идея предложенного метода состоит в том (рис. 9), что из двух записанных бинауральных сигналов для левого и правого уха извлекается временная разница ITD, которая является определяющим локализационным фактором в области низких частот. Для этого сигналы фильтруются с помощью 59 полосовых гамматонных фильтров (т.е. фильтров подобных тем, которые используются в слуховой системе) и одного фильтра низких частот до 200Гц с помощью программы Auditory Tool Box for Matlab [9]. Разница по времени для левого и правого каналов вычисляется для каждой частотной полосы как индекс максимума кросскорреляции между сигналами. В каждой частотной полосе выбирается временной отрезок (frame) длительностью 10 мс, и вычисляется ITD (по расположению кросскорреляционных максимумов). Из этих значений составляется частотно-временная матрица (ITD-matrix-рис. 9). Матрица затем прореживается путем усреднения (sparse Matrix – рис. 9). Следующим этапом является монофонизация бинауральных сигналов – для этого сигналы синхронизируются (сдвигаются по времени один относительно другого). Для того чтобы убрать разницу по интенсивности между сигналами, они фильтруются с помощью эквализационных фильтров (обратная минимально фазовая часть HRTF). После фильтрации бинауральные сигналы суммируются, и получается монофонический сигнал, который вместе с частотно-временной матрицей передается на воспроизводящую часть. Далее сигнал панорамируется по методу Vector Base Amplitude Panning, т.е. подбираются коэффициенты усиления для каждого канала и с учетом частотно-временной матрицы подаются на заданное число каналов, например, по системе 5.1 [9].
Данный метод был только первым этапом в развитии техники upmix, в настоящее время исследования в этом направлении активно продолжаются.
Бинауральный синтез в искусстве записи и воспроизведения звука
Как уже было отмечено выше, бинауральный синтез находит широкое применение в архитектурной акустике (созданная на его базе техника аурализации вывела проектирование помещений на принципиально новый научный уровень), в создании систем виртуальной реальности и мультимедиа, в развитии коммуникационных и информационных систем, в научных (в том числе психоакустических и медицинских) исследованиях.
Особую роль бинауральный синтез имеет в развитии техники записи и воспроизведения звука, соответственно в совершенствовании искусства звукорежиссуры. В настоящее время используется техника многомикрофонной записи; техника записи с помощью системы стереомикрофонов и микрофонов для пространственного звуковоспроизведения (например, типа Soundfield), а также запись на «искусственной голове».
За десятилетия развития звукозаписи искусство звукорежиссерской работы с многомикрофонными записями достигло очень высокого уровня, техника работы с микрофонными системами типа Surround Sound осваивается звукорежиссерами в последние годы, а вот техника записи на «искусственной голове» (ИГ), хотя она известна давно и дает возможность получить действительно пространственный звук при воспроизведении через телефоны и громкоговорители, не получила широкого распространения, поскольку ИГ были достаточно редкими и дорогими приборами, и техника процессорной обработки при последующем воспроизведении не обладала необходимым быстродействием и объемами памяти, поэтому и методы звукорежиссерской работы не были детально отработаны.
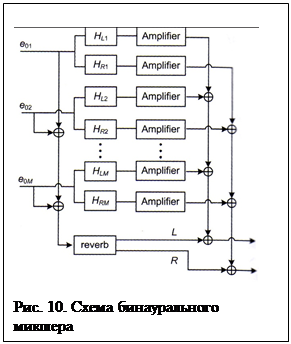
В настоящее время ситуация меняется, приобретается все больше опыта работы с бинауральными записями и соответственно отрабатываются звукорежиссерские приемы. Одновременно с этим созданы так называемые «бинауральные микшерные консоли» [6], позволяющие многоканальные микрофонные записи преобразовывать в бинауральные. Блок-схема такой консоли показана на рис.10. Для сигналов, записанных от М различных микрофонов е01,е02….е0М , реализуется свертка с М-пар импульсных характеристик HRIR, соответствующих различным положениям микрофонов относительно позиции головы, и из них формируются два бинауральных сигнала для левого и правого слуховых каналов (рис.10). Если при этом использовать импульсные характеристики BRIR, записанные в различных помещениях, то переданные сигналы воспроизводят у слушателя пространственные впечатления, соответствующие любым выбранным залам. Такие сигналы предназначены для воспроизведения через стереотелефоны, но если на этапе записи ввести обработку подавления перекрестных связей, то можно записи воспроизводить прямо через громкоговорители. Примером коммерческого программного продукта, реализующего такие возможности, является Panorama [16].
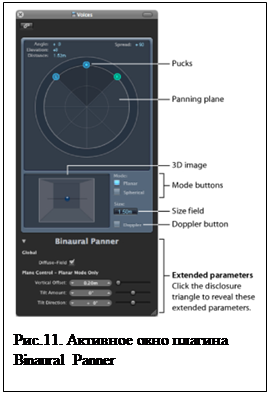
Созданные таким образом бинауральные сигналы могут воспроизводиться через телефоны или громкоговорители, обеспечивая погружение слушателя в пространственный звуковой мир, соответствующий различным окружающим пространствам, при этом могут учитываться как движение головы слушателя, так и перемещения источников (динамическая виртуальная реальность – dynamical VAE). Бинауральные сигналы могут также преобразовываться для воспроизведения как через стерео, так и через пространственные (типа 5.1, 7.1, 22.2 и др.) системы громкоговорителей, так же, как и из стерео и многоканальных сигналов могут быть сформированы бинауральные сигналы. Программные продукты, реализующие эти преобразования, часто реализуются по принципу плагинов DirectX или VST II–III, интегрируемых в любые полнофункциональные звуковые редакторы. Наибольшее распространение получили программы, созданные такими производителями, как: Logic в звуковом редакторе ProTools, IRCAMTOOLS в продукте HEarv3 – Binaural Encoding Plug-In Tool for Headphones и др. Например, Protoolslogic ProBinaural Panning – это специальный плагин пост-процессорной обработки, интегрированный в стандартный микшер редактора LogicPro. Данный плагин позволяет осуществлять бинауральное панорамирование по принципу формирования направления источника сигнала, для создания звукового образа спереди, сзади, сверху, снизу, слева или справа в реальном масштабе времени из стандартного монофонического или стереосигнала. Пользовательский интерфейс программы построен таким образом, чтобы управлять бинауральным сигналом с помощью достаточно простой и наглядной интерактивной визуализации. На рис. 11 представлено активное окно плагина Binaural Panner. Сигнал, который формирует бинауральный паннер, лучше всего подходит для воспроизведения через головные телефоны, однако, разработчики добавили в него и алгоритм (Binaural Post-Processing plug-in) вывода через стандартную стереосистему. Это позволяет воспроизводить сигнал в режиме трансауральной стереофонии через громкоговорители, сохраняя бинауральный эффект. Более подробно данный процесс описан на ресурсе [10]. Все это открывает новые перспективы в развитии звукорежиссерского искусства, искусства звукозаписи, обработки и воспроизведения звука [1].
Рецензенты:
Денисов А.В., доктор искусствоведения, профессор кафедры теории и истории культуры Российского государственного педагогического университета им. Герцена, г. Санкт-Петербург;
Соломонова Н.А., доктор искусствоведения, профессор кафедры звукорежиссуры Негосударственного образовательного учреждения высшего профессионального образования «Санкт-Петербургский гуманитарный университет профсоюзов», г. Санкт-Петербург.
Библиографическая ссылка
Алдошина И.А., Игнатов П.В., Иванов Ю.М. БИНАУРАЛЬНЫЙ СИНТЕЗ В ИСКУССТВЕ ЗАПИСИ И ВОСПРОИЗВЕДЕНИЯ ЗВУКА // Современные проблемы науки и образования. 2015. № 1-1. ;URL: https://science-education.ru/en/article/view?id=17467 (дата обращения: 16.05.2026).