



Введение
В данной работе рассмотрена проблема компьютерной обработки текста на русском языке. Основной задачей данной работы является автоматизированное формирование массива терминов, опираясь на статистические характеристики текстового содержимого и его ключевых единиц, без использования словарных методов обработки текста, за исключением использования словаря шаблонных конструкций и комбинаций слов, сопровождающих определения.
Полученные данные позволяет решить широкий круг проблем, связанных с анализом текстового содержимого, среди них могут быть выделены:
- формирование автоматизированных систем тестирования;
- оценка научного или образовательного материала, на предмет охвата существующих понятий;
- перевод русскоязычного текста;
- автоматизированная коррекция пунктуационных и смысловых ошибок в русскоязычном тексте;
- оптимизация алгоритмов поисковых систем [3];
- проблема распознавания смысла естественного языка компьютерным оборудованием, как подраздел теории искусственного интеллекта.
Предоставленные данные ориентированы на обработку с помощью императивного процедурного языка программирования, но допускает использования логической и функциональной парадигм программирования.
Актуальность проблемы и существующие методы
Актуальной проблемой анализа текстового содержимого является выделение ключевых понятий. Под ключевыми понятиями понимается наиболее значимые термины рассматриваемого текста, которые отражают его основной смысл [2]. Они формируют общее смысловое содержание, позволяя проанализировать глубину рассмотрения предметной области, а также в автоматическом режиме отнести рассматриваемый текст к определенной предметной области.
Существующие методы обработки текста [7] ориентированы в большей мере на выявление закономерностей между отдельными токенами [6] (словами или словосочетаниями составляющими одну смысловую единицу предложения), а также опираются исключительно на словарный анализ. Словарный анализ требует наличия максимально полных баз данных, содержащих слова, а также их взаимосвязи и свойства. Также метод является высоко требовательным к ресурсам, как хранения, так и пополнения и обработки. Метод ограничен представленными базами данных и имеет свойства, которые напрямую зависит от ее полноты. В данном случае появление нового термина, может быть обработано неверно, поскольку он не присутствует в словаре.
Рассматриваемая задача сходна с задачей реферирования [1], которое подразумевает автоматическое формирование аннотации или реферата к представленному текстовому содержимому. Задача имеет более узкую направленность, не требует формирования связного текста из полученных данных, что является основным отличием от реферирования. Также реферирование является избыточным по отношению к представленной задаче.
Ключевые понятия текста имеют широкую область применения, как в области анализа текста, так и в области его автоматической обработки, перевода, а также автоматической проверки на смысловые ошибки [3]. Понятия, предоставленные в тексте, могут быть как общеиспользуемые, так и новые, вводимые в рамках рассматриваемого текста. По этой причине процесс анализа наиболее целесообразно разделить на две отдельно выполняемые задачи: анализ текста на предмет общеиспользуемых [5] терминов и анализ текста на предмет терминов, вводимых и определяемых в рассматриваемом тексте, которые, как правило, предоставляют собой ключевые понятия. Обе задачи кардинально различаются по степени сложности. Поиск вводимых терминов также во многих случаях может быть не реализован словарными методами, поскольку термин в тексте может вводиться впервые или может быть новым и отсутствовать в словаре.
Анализ текстового содержимого на предмет вводимых терминов
Рассмотрим анализ текста на предмет терминов, вводимых в рамках рассматриваемого текста. Для выделения терминов может быть использована следующая последовательность:
- анализ пунктограмм, используемых в рассматриваемом тексте, а также использование шаблонных конструкций, сопровождающих определения нового термина;
- обработка текста на предмет слов и комбинаций, сопровождающих определения нового термина;
- сбор статистики встречаемости слов в тексте с отсеиванием заведомо не являющихся терминами, по полученным статистическим данным.
Анализ пунктограмм [8], а также комбинаций пунктограмм и слов, называемых шаблонными конструкциями, позволяют выделить термины, явно определяемые в тексте, а также является вспомогательным средством на этапе анализа частоты встречаемости, позволяя выявлять сложные предложения и анализировать их как отдельную единицу. При обработке языком программирования, данный этап не требует использование статистических методов, он построен исключительно на использовании теоретических сведений и позволяет достичь высокой степени точности. Этап требует наличия базы шаблонных конструкций, полнота которой напрямую влияет на точность полученных данных. Начальные данные базы формируются вручную, а впоследствии пополняется автоматизировано при взаимодействии с пользователем.
Для решения проблем, не затронутых на предыдущем этапе, производится словарная обработка текста, которая также требует использования теории, но дополняется использованием статистики расположения слов и их комбинаций, отсеиваемых на основе грамматических правил. На данном этапе собирается максимально полная база слов и комбинаций слов, сопровождающих определение новых терминов. Из полученной базы выбирается набор слов и комбинаций, имеющих наибольшую вероятность наличия определения при использовании. Затем производится поиск элементов набора в тексте, что позволяет сузить круг поиска. Таким образом, для каждого элемента набора формируется массив предложений, которые могут содержать определения терминов с определенной вероятностью Pу, которая является вероятностью события, согласно которому рассматриваемый элемент набора слов или комбинаций указывает на наличие определения в данном предложении.
Поскольку вводимые определения, согласно существующим требованиям к оформлению научного текста, как правило, присутствуют в начале текстового содержимого, порядковый номер предложения в тексте также играет весомую роль. По этой причине вводится порядковый коэффициент K, который рассчитывается как отношение порядкового номера предложения к числу всех предложений в тексте согласно формуле 1, где i – номер рассматриваемого предложения, а N – это число всех предложений в тексте.
![]() (1)
(1)
Используя формулу 2, рассчитаем вероятность наличия определения нового термина в рассматриваемом предложении.
![]() (2)
(2)
По полученной вероятности производится сортировка предложений.
Производится сбор статистики встречаемости слов в тексте, то есть производится занесение всех слов текста в один двумерный массив, который содержит анализируемое слово, а также Nпоявл. – количество его появлений. Полученный массив обрабатывается на предмет союзов, предлогов и местоимений, которые затем исключаются. Следующей задачей является поиск элементов массива слов в элементах массива предложений в порядке убывания встречаемости. К каждому слову формируется массив предложений, в которых может быть определено данное слово. Количество появлений слова, а также содержащих его предложений, являются параметрами, определяющими вероятность того, что рассматриваемое слово является термином, поэтому примем ее согласно формуле 3.
![]() (3)
(3)
Производится группировка синонимичных понятий, в результате чего вероятности Pт, группируемых понятий, пересчитывается, а также производится исключение понятий, несущих вспомогательный характер. Затем слова и предложения рассматриваются попарно, в случае если слову соответствует более одного предложения, оно рассматривается с каждым по отдельности, иначе выносится в отдельный массив, а также считается потенциальным определением. Каждой паре формируется вероятность потенциального определения, согласно формуле 4.
![]() (4)
(4)
Используя вероятность потенциального определения, выделяются наиболее вероятные пары, которые далее обрабатываются человеком. На данном этапе целесообразно введение автоматизированного средства, обработки результатов. Предложения, одобренные и не принятые пользователями, заносятся в банк знаний, который в дальнейшем обрабатывает их с целью выявления шаблона, который может быть использован на первом этапе. В случае если одно из предложений, соответствующее полученному шаблону, является не принятым, шаблон в данном случае должен быть переработан или исключен из рассмотрения.
При использовании данного алгоритма, также целесообразным является повтор аналогичных действий как внутри подразделов, так и во всем тексте в целом, а затем сравнение полученных результатов, что позволяет повысить их достоверность.
Визуальное представление данного алгоритма в виде блок-схемы предоставлено на рисунке 1. Его использование в большей степени ориентировано на автоматизацию формирования исходного материала для тестирования знаний обучаемого по существующему материалу преподавателя. При использовании методов автоматизации процесса реферирования, с целью автоматизации формирования тестов, возникают общепринятые понятия рассматриваемой области знаний, что является избыточным.
Использование словарных методов также является нецелесообразным, поскольку они не являются достаточными ввиду разнородности используемых терминов, которые зависят от преподаваемой дисциплины, а также имеют низкое быстродействие. В рассматриваемом методе решаются данные недостатки за счет вероятностного характера алгоритма и исключения общепринятых понятий из рассмотрения.
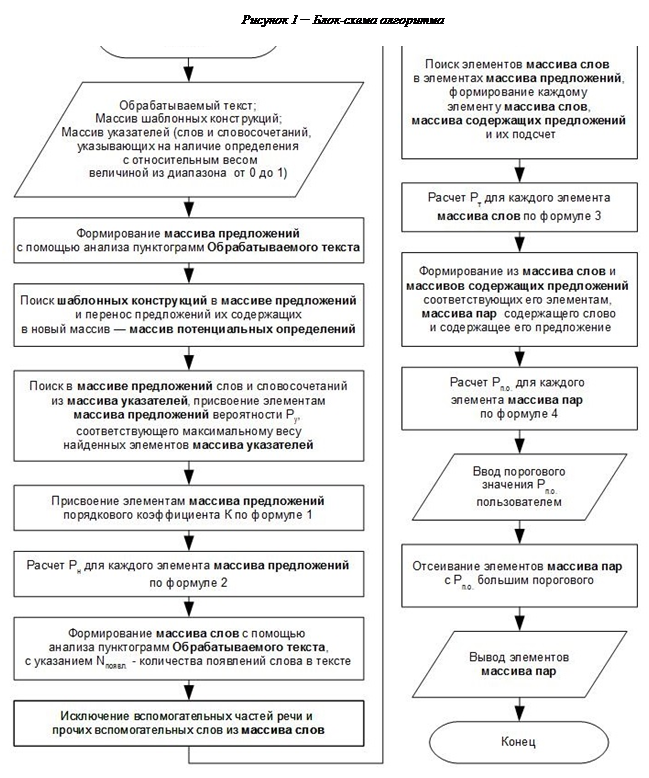
В программном изделии для автоматизации формирования тестов взаимодействие с пользователем, при использовании данного алгоритма, является необходимым, поскольку в выходных данных алгоритма могут присутствовать ложные элементы, которые должны быть исключены. При одобрении элементов пользователем, они подвергаются обработке, с целью выявления шаблонных конструкций и слов-указателей, которые могут быть использованы при повторном использовании приложения, что позволяет оптимизировать последующие результаты. Наличие данного взаимодействия позволяет решить следующие проблемы:
- недостаточность базы шаблонных конструкций, а также неточность некоторых шаблонных конструкций, которая приводит к появлению ложных элементов и отсутствию истинных;
- недостаточность базы слов и их комбинаций, которые сопровождают определения;
- выявление дополнительных вероятностных взаимосвязей, позволяющих повысить точность обработки.
Алгоритм может быть реализован с использованием языка высокого уровня, имеющего функции или библиотеки обработки текста. Также при его использовании достигается более высокая производительность по отношению к словарным методам.
Заключение
В данной работе ключевые понятия рассматриваются как отдельный класс распознаваемых элементов текста, написанного на естественном языке. Данная работа имеет большую направленность к области реферативной обработки текста, которая заключается в выявлении набора ключевых высказываний, описывающих содержимое текста. Большинство методов, используемых для реферирования, опираются на словарные методы, которые требуют наличия словарей, имеющих набор существующих терминов. Предложенный метод имеет исключительно вероятностный характер.
Рецензенты:
Колбанев М.О., д.т.н., профессор СПбГУСЭ, кафедра «Прикладные информационные технологии», г. Санкт-Петербург.
Татарникова Т.М., д.т.н., доцент, профессор, Институт информационных систем и защиты информации СПбГУАП, г. Санкт-Петербург.
Библиографическая ссылка
Белая Т.И., Пасечник П.А. ВЫДЕЛЕНИЕ КЛЮЧЕВЫХ ПОНЯТИЙ В ТЕКСТОВОМ СОДЕРЖИМОМ С ИСПОЛЬЗОВАНИЕМ СТАТИСТИЧЕСКОЙ ОЦЕНКИ // Современные проблемы науки и образования. – 2014. – № 3. ;URL: https://science-education.ru/ru/article/view?id=13485 (дата обращения: 20.04.2024).