



Вопросы, связанные с обеспечением безопасности работы в сети Интернет, с каждым днем встают все более остро. С одной стороны, необходимо обеспечить требуемую меру анонимности пользователя. С другой стороны, целесообразность идентификации пользователей назревает, например, в аспекте защиты информационных систем от различного рода злоумышленников. И в том и в другом случае возникает задача оценивания возможности идентификации пользователей веб-ресурсов.
Для решения данной задачи могут использоваться как качественные, так и количественные показатели. Качественные показатели оценивают, как правило, с помощью метода экспертных оценок [2]. Они могут характеризовать, например, географическое положение, национальную и ведомственную принадлежность веб-ресурса, объем запрашиваемых регистрационных сведений, необходимость включения cookie, Java-скриптов и т.п. для работы с веб-ресурсом, перенаправления данных на иные веб-ресурсы, характер скрытого сбора данных о пользователе и т.д. Показатели, характеризующие программно-аппаратную среду пользователя, и показатели, характеризующие информационную деятельность пользователя в Интернете, должны отражать, прежде всего, степень влияния передаваемой пользователем веб-ресурсу информации на возможность его идентификации.
К основным направлениям оценивания показателей возможности идентификации пользователей веб-ресурсов относятся:
- выявление веб-ресурсов, способных идентифицировать своих посетителей, и оценивание достоверности идентификации;
- анализ объема информации о пользователе, доступной с его рабочего места, используемого для выхода в Интернет;
- анализ защищенности рабочего места пользователя;
- анализ технических требований веб-ресурса для работы с ним;
- анализ информативности запросов пользователя с точки зрения оценки возможности выявления его информационного интереса;
- анализ индексов популярности веб-ресурсов;
- анализ трафика, передаваемого веб-ресурсу;
- анализ объема и характера передачи данных веб-ресурсом на сайты разработчиков и сторонние, или «темные», сайты;
- накопление и анализ статистики о характере сбора данных веб-ресурсом и т.д.
Для количественной оценки возможности идентификации пользователей веб-ресурсов требуется ввести показатель, учитывающий возможность явной (поисковый запрос, регистрация и т.п.) или неявной (посредством технологий скрытого сбора данных) передачи веб-ресурсу определенного набора признаков, позволяющих идентифицировать пользователя. Следует отметить, что поскольку для сбора данных веб-ресурс использует достаточно широкий спектр технологий, перечень признаков весьма разнообразен. В качестве примера можно указать, что при помощи объекта Screen доступно получение разрешения экрана (браузера) и глубины цвета, с использованием средств AJAX на веб-ресурс могут передаваться параметры ввода информации в поля с целью сбора статистики о скорости ввода и типовых ошибках пользователя [5], а с помощью Navigator.plugins можно получить список всех установленных в браузере плагинов, кроме IE.
В целях решения поставленной задачи могут быть использованы различные подходы. К примеру, заслуживает внимания способ идентификации пользователя [1], в основе которого лежит мера соответствия полученных признаков действительному пользователю в условиях их возможной подмены. Однако в условиях наличия значительной массы пользователей, работающих с популярными веб-ресурсами, следует подойти, напротив, с точки зрения различаемости пользователей при возможной недостаточности набора признаков для однозначной идентификации. При этом наиболее целесообразным представляется использование вероятностных подходов.
При работе в Интернете пользователь и его рабочее место как человеко-машинная система характеризуются совокупностью m признаков, которые в том или ином случае могут оказаться доступными веб-ресурсу. Пусть N – число пользователей (субъектов), взаимодействующих с идентифицирующим их веб-ресурсом. Каждый признак xi имеет ai исходов с вероятностями pij, j=1,…ai. Тогда M – число всех возможных различных наборов признаков, или профилей:
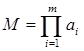 .
.
Вероятность того, что случайный субъект имеет профиль Y=<y1,…ym>, в предположении, что реализации признаков независимы, составляет
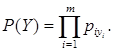
Тогда вероятность того, что субъект имеет уникальный профиль (то есть все иные субъекты имеют профили, не совпадающие с Y), определяется как
![]() .
.
Величина R(Y), являясь вероятностью однозначности профиля, служит мерой возможности идентификации субъекта, обладающего конкретным набором признаков (профилем). Однако для веб-ресурса, идентифицирующего пользователя, интересна оценка R для априори неизвестного Y. Предположим вначале, что реализации признаков равновероятны: pij=1/ai. Тогда
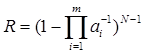 .
.
Обозначая hi=log2ai, получаем
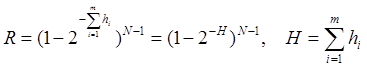 . (1)
. (1)
Для рассмотренного случая справедливо
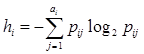 . (2)
. (2)
Полученная величина hi, которую будем называть информативностью признака, соответствует двоичной энтропии [3], что дает возможность распространить полученные для H и R выражения на общий случай не равновероятных реализаций признаков. Смысл информативности признака состоит в том, что ее можно рассматривать как количество информации о пользователе, причем знание каждого признака уменьшает исходную энтропию как меру неопределенности профиля пользователя.
Так, например, по результатам эксперимента, проведенного организацией Electronic Frontier Foundation в рамках проекта panopticlick.eff.org [6], были получены некоторые оценки энтропии компонентов отпечатка браузера (табл. 1).
Таблица 1. Оценки энтропии компонентов отпечатка браузера по результатам эксперимента panopticlick.eff.org
|
Компоненты отпечатка браузера |
Энтропия компонента (бит) |
|
Заголовок User Agent |
10,0 |
|
Список установленных плагинов |
15,4 |
|
Список установленных шрифтов |
13,9 |
|
Установки видеоподсистемы |
4,83 |
|
Поддержка supercookies |
2,12 |
|
Заголовок http accept |
6,09 |
|
Временная зона |
3,04 |
|
Включенность cookies |
0,353 |
Однако на практике неизбежна ситуация, когда по имеющимся признакам можно в определенной степени судить о возможных значениях других, то есть имеет место корреляция признаков, снижающая их суммарную информативность. Кроме того, зачастую заведомо неизвестно, какие из признаков будут доступны веб-ресурсу. Следовательно, требуется учет возможности взаимной зависимости (корреляции) признаков, а также вероятностного характера их добывания веб-ресурсом.
Суммарную информативность последовательного анализа m признаков x1,…, xm можно рассчитать из выражения [4]
![]()
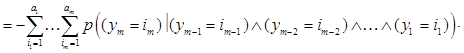
![]() .
.
Пусть задано распределение вероятностей j-го признака при условии k-й реализации i-го признака, которые обозначим ![]() . Тогда в случае yi=k информативность признака xj вычисляется как
. Тогда в случае yi=k информативность признака xj вычисляется как
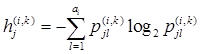 ,
,
а с учетом всех реализаций признака Xi
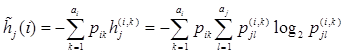 .
.
Соответствующие расчеты результирующей информативности признаков для большого их числа достаточно сложны, поэтому предлагается использовать следующий подход. Пусть γi – вероятность добывания веб-ресурсом признака xi, i=1,…,m. Определим величину![]() , имеющую смысл снижения информативности j-го признака за счет его корреляции с i-м признаком, и составим таблицу (табл. 2).
, имеющую смысл снижения информативности j-го признака за счет его корреляции с i-м признаком, и составим таблицу (табл. 2).
Таблица 2. Схема таблицы попарных снижений информативности признаков
|
------ |
X1 |
X2 |
X3 |
X4 |
… |
Xm-1 |
Xm |
γ |
|
X1 |
------ |
?h12 |
?h13 |
?h14 |
… |
?h1(m-1) |
?h1m |
γ1 |
|
X2 |
?h21 |
------ |
?h23 |
?h24 |
… |
?h2(m-1) |
?h2m |
γ2 |
|
… |
… |
… |
… |
… |
… |
… |
… |
... |
|
Xm-1 |
?h(m-1)1 |
?h(m-1)2 |
?h(m-1)3 |
?h(m-1)4 |
… |
------ |
?h(m-1)m |
γm-1 |
|
Xm |
?hm1 |
?hm2 |
?hm3 |
?hm4 |
… |
?hm(m-1) |
------ |
γm |
Будем исходить из того, что признаки следует ранжировать и последовательно выбирать максимальное ?h каждого признака, причем соответствующие ?h выбираемые пары признаков не должны повторяться. Для этого на первом шаге выберем строку, содержащую максимальный элемент таблицы:
![]()
![]() .
.
Следующий максимальный элемент будем выбирать из строки, номер которой равен номеру столбца выбранного элемента:
![]() ;
;
![]() ;
;
![]() ,
,
где ?h(t) – элементы таблицы на t-м шаге с учетом вычеркивания выбранных строк и столбцов.
В результате после (m-1) шагов получим
![]() ,
,
где H рассчитывается согласно (1) и (2). В том случае, если признаки являются независимыми, расчет упрощается:
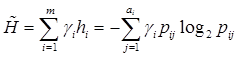 .
.
Таким образом, оценка уровня возможности идентификации с учетом взаимной зависимости признаков субъекта может быть получена в соответствии с (1):
![]() ,
,
а при N>>1
![]() .
.
Для определения суммарной информативности признаков, необходимой для идентификации субъекта с заданной вероятностью Q при N>>1, следует воспользоваться выражением
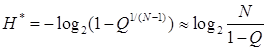 .
.
Таким образом, предложенный способ позволяет на основе имеющихся статистических данных о распределении признаков пользователей оперативно оценивать степень возможности их идентификации веб-ресурсом. В настоящее время в локальной вычислительной сети учебной лаборатории развернут тестовый сервер, осуществляющий сбор и накопление статистики обращений в целях проработки технологий, связанных с рассматриваемыми вопросами, и анализа их эффективности. Полученные на данный момент результаты позволяют положительно оценивать перспективы использования предложенного способа анализа возможности идентификации пользователей веб-ресурсов на основе энтропийного подхода.
Рецензенты:
Хомоненко А.Д., д.т.н., профессор, профессор кафедры математического и программного обеспечения ФГКВОУ ВПО «Военно-космическая академия имени А.Ф. Можайского» Министерства обороны Российской Федерации, г. Санкт-Петербург.
Басыров А.Г., д.т.н., доцент, начальник кафедры информационно-вычислительных систем и сетей, ФГКВОУ ВПО «Военно-космическая академия имени А.Ф. Можайского» Министерства обороны Российской Федерации, г. Санкт-Петербург.
Библиографическая ссылка
Захаров И.В., Забузов В.С., Фомин С.И., Фомин С.И., Эсаулов К.А. СПОСОБ АПРИОРНОЙ ОЦЕНКИ ВОЗМОЖНОСТИ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ ВЕБ-РЕСУРСОВ НА ОСНОВЕ ЭНТРОПИЙНОГО ПОДХОДА // Современные проблемы науки и образования. – 2014. – № 1. ;URL: https://science-education.ru/ru/article/view?id=12004 (дата обращения: 19.04.2024).